第六章 媒体采集、播放和时序
- 发送端行为
- 媒体采集和编码
- RTP 包生成
- 接收端行为
- 包的接收
- 播放缓冲区
- 播放点自适应(adapting the playout point)
- 解码、混流(mixing)和播放
这一章我们不再讨论网络和协议,转入 RTP 系统设计。实现 RTP 需要兼顾很多功能,根据需求,有些是必须得,有些是可选得。本章主要讨论媒体采集、播放时序两个基本功能。后面章节描述了提高接收质量,减少资源开销的方法。
我们先讨论发送端的行为:媒体采集和编码、RTP 包封装以及底层的媒体时序模型。后面,主要讨论接收端,在不确定传输场景下,媒体播放以及时序恢复的问题。接收端最关键的部分是播放缓冲区是设计,本章的大部分内容都将集中在这方面的讨论。
最重要的是要记住,发送端和接收端在 RTP 的规范的允许下,实际可以有很多实现方案。这里讲的设计是其中一种考虑各种制约,折中的实现方案。实战中,应该根据特定的场景设计特定的方案(文献中描述了很多实现方案,例如:McCanne 和 Jacoboson 描述了一个有影响力的RTP视频会议系统设计 )。
发送端的处理
如第一章 RTP 介绍中所述,发送端负责采集音视频数据(无论是实时采集还是来自文件),对音视频数据进行编码后传输,并封装 RTP 数据包。它还可以通过根据接收端反馈调整传输的媒体流的方式,进行纠错和拥塞控制。第一章中的图 1.2 显示了这个过程。
发送端首先将未编码的媒体数据 (音视频采样) 读入到一个缓冲区,然后从中产生编码帧。帧数据可以用不同的编码算法进行编码,编码后的帧数据可能同时依赖之前和之后的数据。下一节,媒体的采集和编码,描述了这个过程。
被编码的帧会被分配一个时间戳和一个序列号,并加载到 RTP 包,等待发送。如果一个帧信息太大,不能装到一个包中,它可能被分割成几个包进行传输。如果一个帧很小,可以将几个帧绑定到一个 RTP 包中。本章后面的《RTP 包的封装》一节,描述了这些功能,只有在有效负载(payload)支持的情况下,这两种功能才能实现。根据所使用的纠错方案,可以使用信道编码器来封装纠错数据包,或者在传输之前重新排序帧(第八章和第九章讨论了错误隐藏和错误恢复)。发送端将针对其封装的媒体流,以 RTCP 数据包的形式封装定期状态报告。它还将收到来自其他参与者的接收质量反馈,并可能使用这些信息来调整其传输。RTCP 在第五章 RTP 控制协议中有详细描述。
媒体采集和编码
无论是传输音频还是视频,媒体采集过程在本质上是相同的:采集到未编码的数据,如果需要将其转换为合适的编码格式,然后调用编码器来封装编码帧。然后编码帧会传递到打包代码,并封装一个或多个 RTP 数据包。音视频采集相关的问题,将在接下来的两章中讨论,然后我么也会讨论对打包预先录制的内容所引发的问题。
音频的采集和编码
考虑到音频采集的特点,图 6.1 显示了在通用工作站上的采样过程:声音被采集、数字化并存储到音频输入缓冲区。输入缓冲区通常在收集到了固定数量的样本之后才能提供给上层逻辑。大多数音频采集 api 会以固定时长的帧,从输入缓冲区返回数据,直到采集足够的样本以形成完整的帧为止,在这个过程中 API 会被阻塞住。这会带来一些延迟,因为直到采样完最后一个样本(sample)之后,帧中的第一个样本才可用。如果我们可以选择,用于交互用途的应用程序,应选择最接近编码器一帧时长的缓冲大小(通常为 20ms 或者 30ms),来减少延迟。
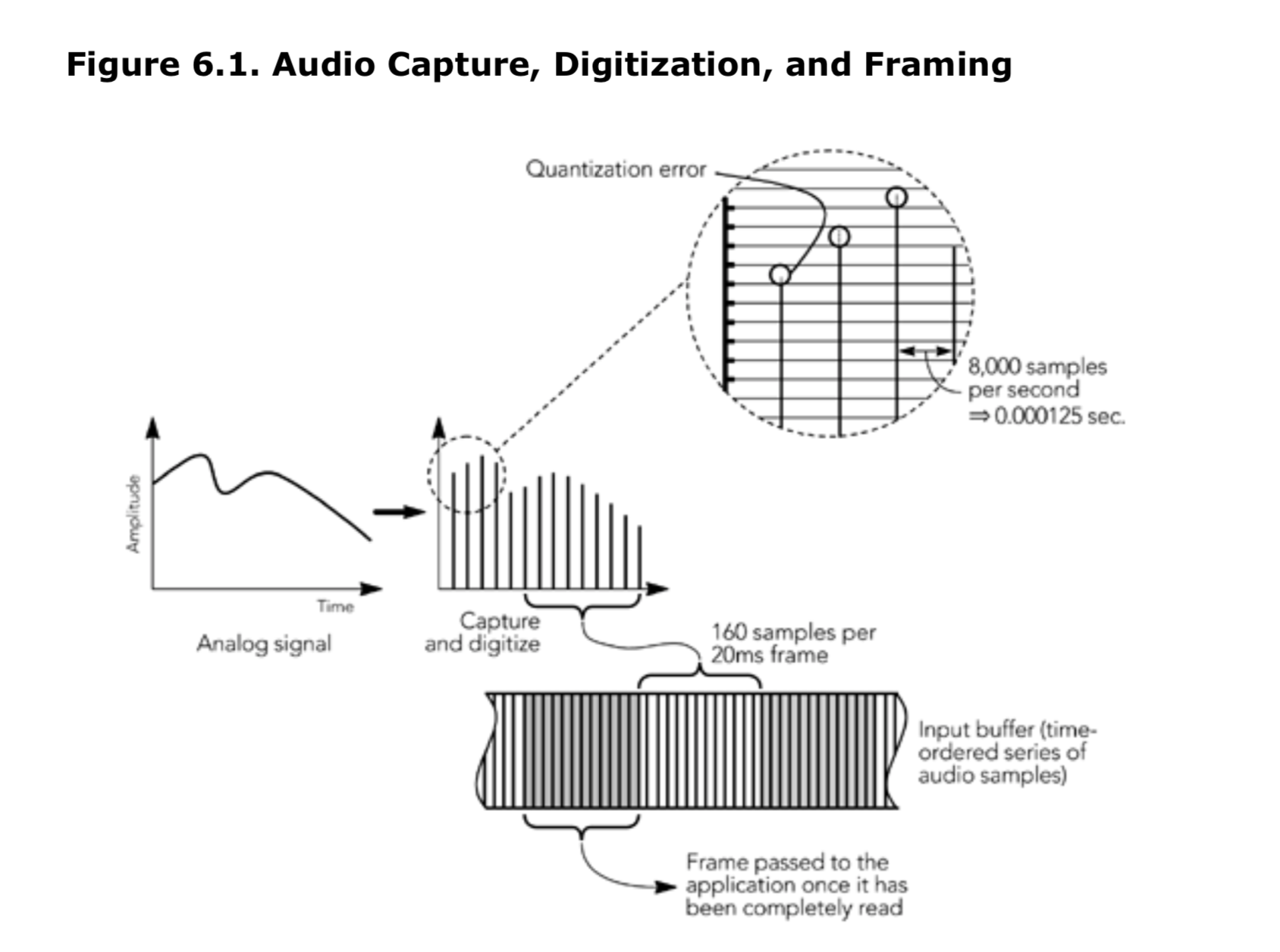
应用可以用不同的采样类型和采样率,从采集设备采集未编码的音频。常见的音频采集设备可以采样:
- 8bit、16bit或 24bit 的采样;
- 量化方式可以使用线性、μ-law 或 A-law,
- 采样率可以从 8000 到 96000 之间,
- 可以有单声道或多声道。根据采集设备的功能和编码器的不同, 在实际使用之前,还可以改变采样格式,例如更改采样率或更改量化方式从线性到 μ-law。转换音频格式算法,超出了本书的范围,标准的信号处理类书籍可以作为参考。
一种最常见的音频格式转换就是转换采样率,例如当采集设备是一个采样率,但是编码器设置的是另一种速率的时候(例如,该设备以 44.1KHz 固定速率运行,以支持高质量的 CD 播放,但是我们希望使用 8KHz 的语音编码进行传输)。虽说采样率可以直接以任意的数值进行转换,但是对于整数倍的采样率之间的转换,效率和准确度才是最高的。当选择音频硬件的采集模式时,应考虑采样率转换的计算要求。其他音频格式的转换,例如转换在线性量化和 μ-law 之间转换,开销会比较低,可以在软件中执行。
音频采样会传递到编码器进行编码。 根据编解码器的不同,状态可能会在帧(编码上下文)之间保持不变,必须与每个新的数据帧一起供编码器使用。 一些编解码器,尤其是音乐编解码器,其编码基于一系列未编码的帧,而不是孤立地基于未编码的帧。 在这些情况下,编码器可能需要传递几帧音频,或者可能在内部缓存帧并仅在接收到几帧后才产生输出。 一些编解码器会生成固定大小的帧作为其输出,产生可变大小的帧。 可变大小的帧通常根据所需的质量或信号内容从一组固定的输出速率中进行选择; 但是,实际上真正可变速率的很少。
许多语音编解码器通过静音抑制来执行语音活动检测,以检测和抑制仅包含静音或背景噪声的帧。 被抑制的帧不被发送,或者偶尔被低速率舒适噪声包所代替。 这样做可以大大节省网络流量,特别是如果使用统计多路复用的时候,则更能有效得利用有限容量的信道。
视频的采集和编码
视频采集设备通常在处理完整的视频帧,而不是返回逐行扫描线或隔行扫描的场。许多设备提供了以降低的分辨率对帧进行降采样或返回采集帧的子集的功能。帧可能具有一定分辨率的大小,并且采集设备可能会返回各种不同格式、颜色空间、深度和降采样的帧。
根据所使用的编解码器,可能需要先从采集格式转换到可以使用的格式,然后才能使用该帧。 这种转换的算法不在本书的讨论范围之内,但是任何标准的视频信号处理书都将提供各种可能的方法,具体取决于所需的质量和可用资源。目前最常见的可能是在 RGB 和 YUV 颜色空间之间进行转换。 此外,色彩抖动和重采样也经常使用。 这些转换非常适合硬件加速,如许多处理器体系结构中存在的单指令多数据(SIMD)指令(例如,Intel MMX 指令,SPARC VIS 指令)。 图 6.2 说明了视频采集的过程,并以 YUV 格式采集的 NTSC 信号为例,在使用前将其转换为 RGB 格式。
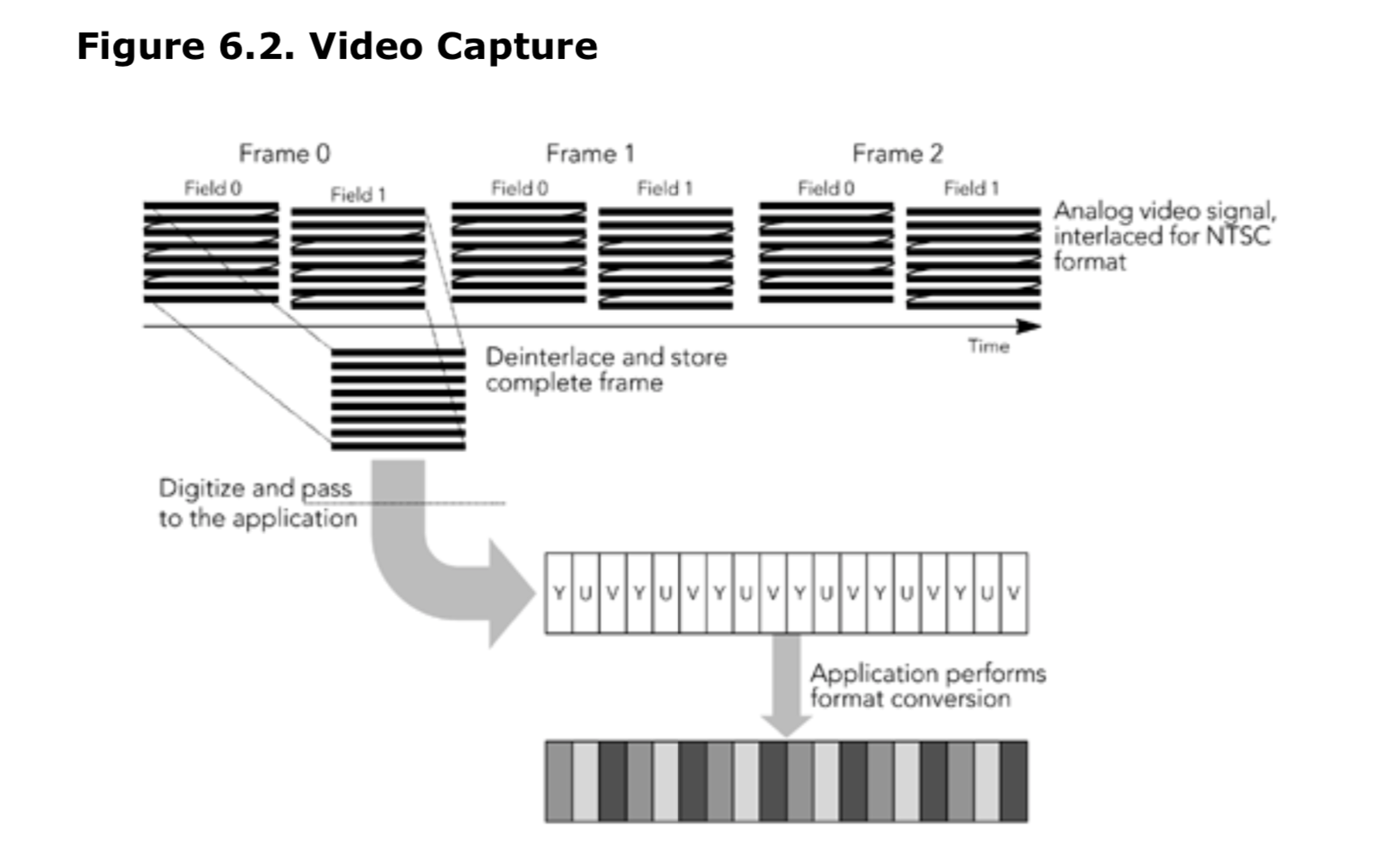
我们采集视频,加入缓冲区,然后再传递给编码器进行编码。缓冲区大小取决于编码方案;大多数视频编解码器使用帧间编码,每一帧都依赖于前后的帧。帧间编码可能需要编码器延迟特定的帧的编码,需要等待采集到它所依赖的帧为止。编码器将在帧之间维护状态信息,该信息必须与视频帧一起提供给编码器。
对于音视频,采集设备都可以直接产生编码媒体,而不是分为单独的采集和编码阶段。 这在专用硬件上很常见,但是某些视听工作站也具有内置编码功能。 以这种方式工作的采集设备可简化 RTP 实现,因为 RTP 实现的时候不需要包括单独的编解码器了,但是它们可能将适应范围限制为时钟偏移(clock skew)和/或网络抖动,如本章稍后所述。
无论媒体类型是什么以及如何编码,采集和编码阶段的产出都是一系列编码帧,每个编码帧都有关联的采集时间。 这些帧被传递到 RTP 模块,以进行打包和传输,如下一节《RTP 包的封装》所述。
使用预先录制的内容
从预先录制和编码的内容文件流式传输时,媒体帧将以与直播内容几乎相同的方式传递到打包程序。 RTP 规范没有区分直播媒体和预录媒体,发送端无论如何封装帧,都以相同的方式从编码帧解封装为数据包。
特别是,当开始流式传输预先录制的内容时,发送端必须生成新的 SSRC,并为 RTP 时间戳和序列号选择随机初始值。 在流传输过程中,发送端必须准备处理 SSRC 冲突,并且应生成并响应该流的 RTCP 包。 另外,如果发送端实现了控制协议(例如 RTSP),允许接收端在媒体流中暂停或查找(seek),则发送端必须跟踪此类交互,以便可以将正确的编号和时间戳插入 RTP 数据包中(这些问题在第 4 章《RTP 数据传输协议》中讨论过了)。
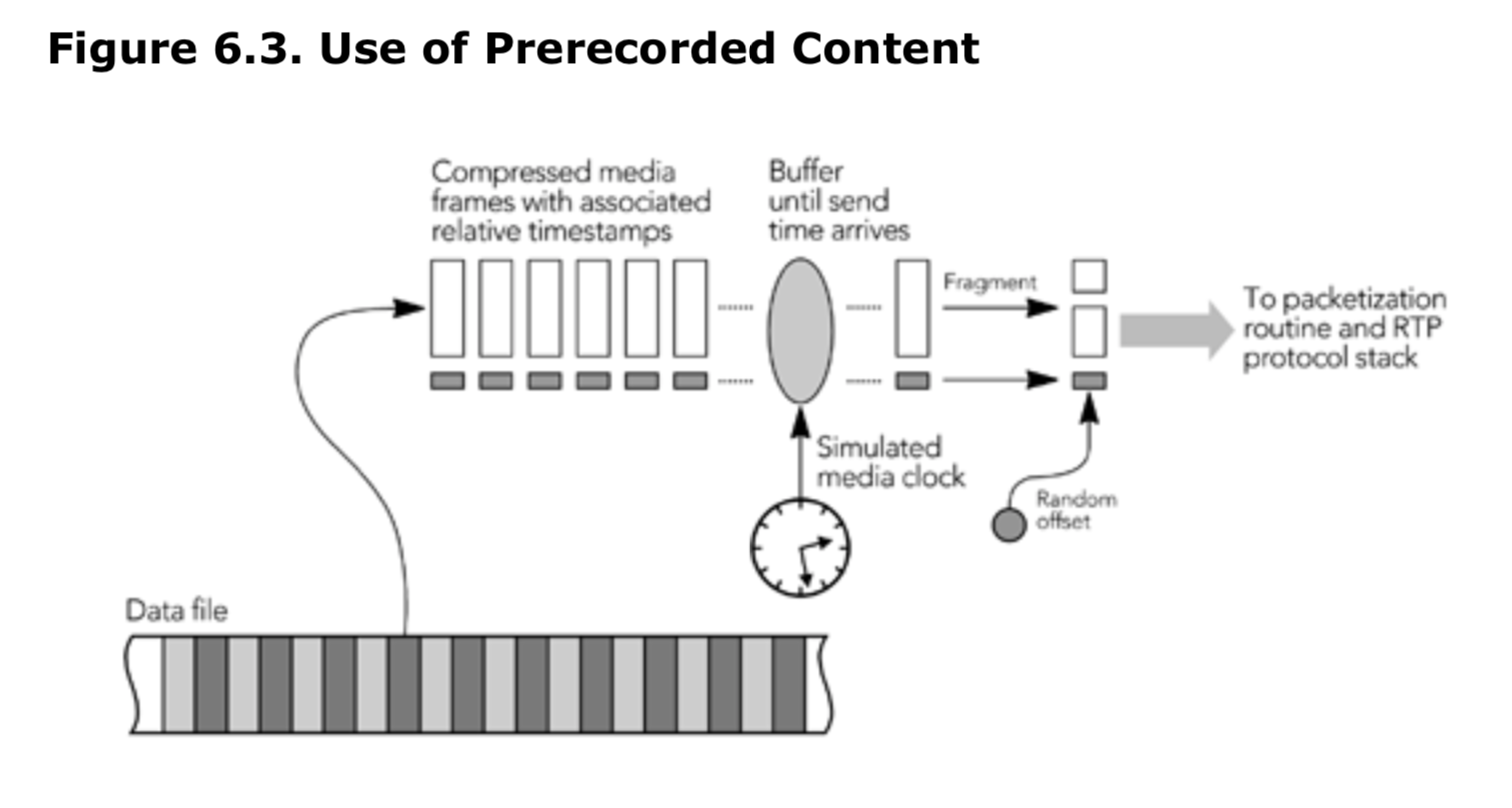
需要实现 RTCP,并确保序列号和时间戳正确,这意味着发送端不能简单地将完整的 RTP 数据包存储在文件中,也不能直接从文件流式传输。 相反,如图 6.3 所示,必须实时存储和打包媒体数据帧。
封装 RTP 包
生成编码帧后,会将它们传递到 RTP 打包程序。 每个帧都有一个关联的时间戳,可从中导出 RTP 时间戳。 如果有效负载格式支持分段,则将过大的帧分段以适合网络的 MTU(通常仅视频需要)。最后,为每个帧生成一个或多个 RTP 数据包,每个数据包都包括媒体数据和任何所需的有效负载头。 媒体数据包和有效负载头的格式是根据所用编解码器的有效负载格式规范定义的。数据包生成过程的关键部分是为帧分配时间戳,分割过大的帧以及生成有效负载包头。在以下各节中将更详细地讨论这些问题。
除了直接表示媒体帧的 RTP 数据包之外,发送端还可以生成纠错包,并可以在传输之前对帧进行重新排序。 这些过程在第 8 章《错误隐藏》和第 9 章《错误恢复》中进行了描述。 在发送 RTP 数据包之后,与这些数据包相对应的缓冲媒体数据最终将被清空。 发送端不得丢弃纠错或编码过程中可能需要的数据。此要求可能意味着发送端必须在发送完相应的数据包后将数据缓冲一段时间,具体取决于所使用的编解码器和纠错方案。
时间戳与 RTP 的时序模型
RTP 时间戳表示帧数据第一个比特位的采样时刻(sampling instant)。它从一个随机初始值开始,速率递增和媒体类型相关。
在采集实时媒体流期间,采样时刻就是从视频帧采集器或音频采样设备采集媒体的时间。如果要同步音视频,必须确保考虑了不同采集设备中的处理延迟。对于大多数音频有效负载格式,每帧的 RTP 时间戳增量等于从采集设备读取的样本数量。MPEG 音频,包括 MP3,它使用 90kHz 媒体时钟,以与其他 MPEG 内容兼容。对于视频,根据时钟和帧速率,对于采集的每个帧,RTP 时间戳都会以标称的每帧值递增。 大多数视频格式使用 90kHz 时钟,因为这样可以为常见的视频格式和帧速率提供整数时间戳记增量。 例如,如果使用带有 90kHz 时钟的有效负载格式以每秒(大约)29.97 帧的 NTSC 标准速率发送,则 RTP 时间戳将每个数据包增加 TexactlyT 3003。
对于从文件流式传输的预录制内容,时间戳给出了播放序列中帧的时间,加上一个恒定的随机偏移量。 如第 4 章《RTP 数据传输协议》所述,从中导出 RTP 时间戳的时钟必须以连续和单调的方式增加,不需要考虑查找(seek)操作或播放中的暂停。 这意味着时间戳并不总是对应于帧从文件开始的时间偏移; 而是以自播放开始以来的时间轴为测量基准。
时间戳是按帧分配的。 如果将一个帧分成多个 RTP 数据包,那么组成该帧的每个数据包都将具有相同的时间戳。
RTP 规范不保证媒体时钟的分辨率、准确性或稳定性。发送端负责选择合适的时钟,并为所选应用提供足够的准确性和稳定性。接收端知道标称时钟速率,但通常不了解时钟精度。除非应用程序具有相反的特定知识,否则应用程序在发送端和接收端都应对媒体时钟的可变性具有鲁棒性。
RTP 数据包和 RTCP 发送端报告中的时间戳表示发送端媒体的时序:采样过程的时序以及采样过程与参考时钟之间的关系。 接收端期望根据该信息来重建媒体的时序。 请注意,RTP 时序模型没有说明何时播放媒体数据。 数据包中的时间戳给出了相对时序,RTCP 发送端报告提供了流间同步的参考,但 RTP 并未说明接收端可能需要的缓冲量或包的解码时间。
尽管很好地定义了时序模型,但 RTP 规范并未提及用于重建接收端时序的算法。这是有意为之的:播放算法的设计取决于应用程序的需求,按需实现。
分段 Fragmentation)
超出网络最大传输单位(MTU)的帧必须在传输之前分成几个 RTP 数据包,如图 6.4 所示。每个分段都有该帧的时间戳,并可能有一个额外的有效负载包头来描述分段。
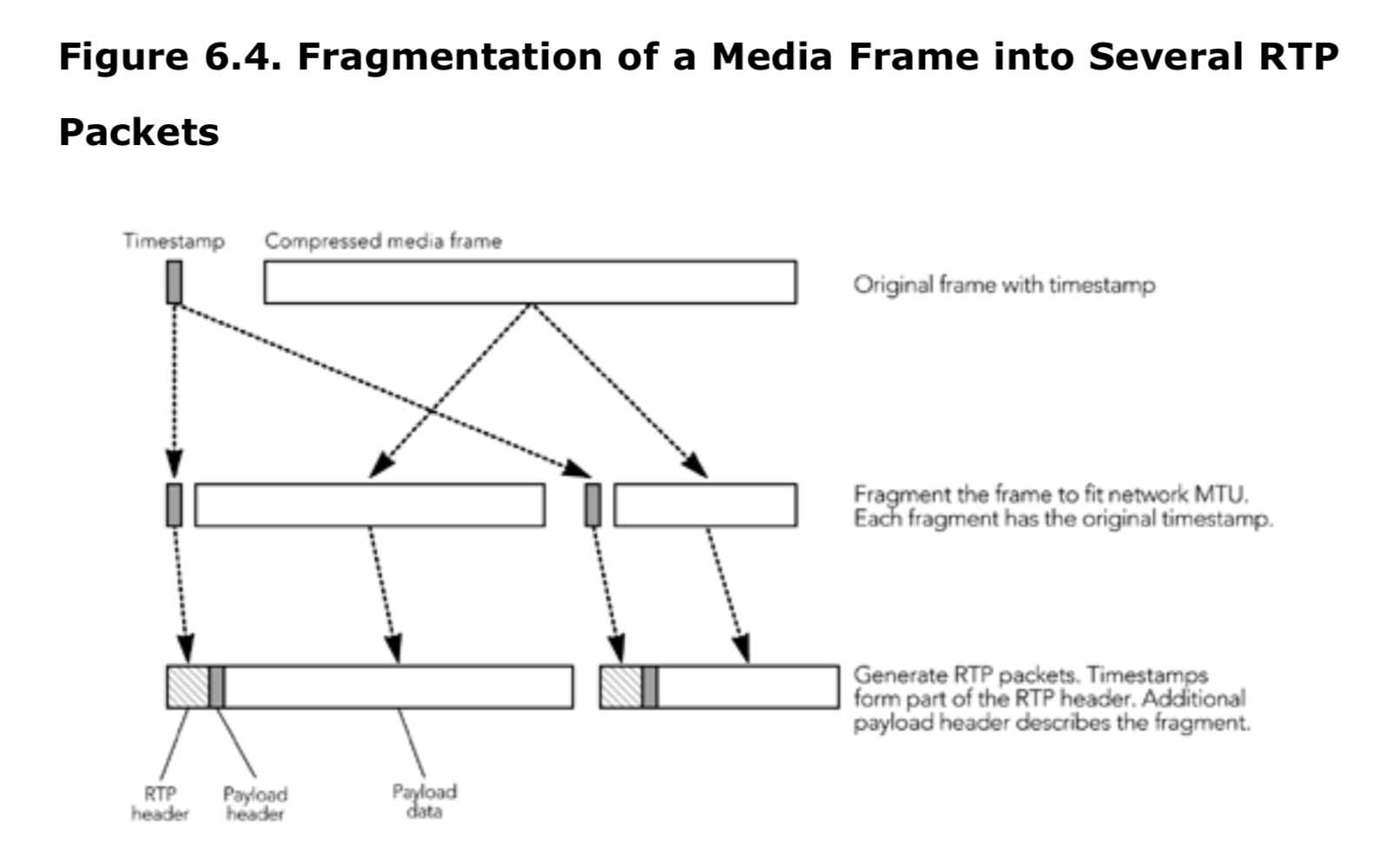
在丢包的情况下,分段的处理对媒体质量至关重要。最理想的情况是独立解码每一个分段。否则单个分段的丢失会将导致整个帧都被丢弃, 这是我们不希望看到的。可能需要在分段的时候制定一些规则,根据这些规则,负载数据可以在适当的位置做分割,并加上负载头,以帮助接收端在某些片段丢失的情况下还可以使用。这些规则需要编码器的支持,以生成既符合有效负载格式的打包规则又适合网络 MTU 的片段。
如果编码器不能生成适当大小的片段,发送端可能必须使用任意的片段。可以通过 RTP 层上的应用程序或使用 IP 分段的网络来实现分段。如果丢失了任意分段的帧的某些片段,则很可能必须丢弃整个帧,从而大大降低质量(Handley 和 Perkins 更详细地描述了这些问题)。
当为每帧封装多个 RTP 包时,发送端必须在以下方式中选择其一:一次性发送数据包(sending the packets in single burst)还是拆分后的多个数据包分散开传输在帧间隔中。一次性发包会减少端到端的延迟,但是可能会超出网络或接受主机的缓冲区大小。出于这个原因,一般都是选择发送端在帧间隔内及时分发包。无论是否存在其他的场景,这对于发送端,特别是高速发送端,这都是非常重要的办法。
负载的格式-特殊的头信息
除了 RTP 报头和媒体数据之外,包通常还包含一个额外的特定于负载的包头。此包头由使用中的 RTP 有效负载格式规范定义,并在 RTP 和编解码器之间,提供了一个适配层。
有效负载包头的典型用法是使编解码器(该编解码器不适合在有损数据包网络上使用)在 IP 上工作,以提供错误恢复能力或支持分段。精心设计的有效负载包头可以大大提高有效负载格式的性能,实现者应注意以正确生成这些包头,并使用提供的数据来修复接收端丢包的影响。
在第四章《RTP 数据传输协议》中,“负载头信息”这一节详细讨论了有效负载头的使用。
接收端的处理
正如第一章《RTP 介绍》中所强调的,接收端负责从网络中收集 RTP 数据包,并且修复或纠正丢失的数据包,恢复时序,解码媒体,并将结果显示给用户。此外,接收端需要发送 接收质量报告,以便发送端能够根据网络特性调整传输策略。接收端通常还将维护会话中的参与者数据库,以便能够向用户提供其他参与者的信息。第一章的图 1.3 显示了接收端的框图。
接收过程的第一步是收集来自网络的数据包,验证它们的正确性,并将它们插入到发送端对应的输入缓存队列中。这个处理并不难,且实现独立于媒体格式。下一节 包接收将描述这个过程。
除了接受缓存队列,接收端的其实部分实现,都可能和媒体类型相关。应用将数据包从输入队列中移除,并传递到信道编码程序中,用来做纠错(第九章描述了纠错),但是这一步也不是必要的。在信道编码器之后,数据包会被插入到特定源的播放缓冲区中,这些数据包将一直保留,直到收到完整的帧。这个过程会消除网络原因造成的数据包乱序。在实现 RTP 时,计算每个步骤的延迟量是最关键的方面之一,本章后面的《播放缓冲区》一节,将对此进行解释。自适应播放点(playout point)这部分,描述了如何在不中断媒体播放的情况下调整时序。
在到达播放时间前的某个时间段,数据包会被恢复成完整的帧,并且修复损坏及丢失的帧(第八章《错误隐藏》,介绍了修复的算法),并对帧进行解码。最后,为用户呈现媒体数据。 根据媒体格式和输出设备的不同,可能可以单独播放每个流,例如,在自己的窗口中显示几个视频流。 或者,可能有必要将所有来源的媒体混合到单个流中进行播放-例如,通过一组峰化器组合多个音频源以进行播放。本章的最后一部分 -- 解码、混流(mixing)和播放 -- 描述了这些操作。
RTP 接收端的实现相比于发送端的实现更为复杂。这种复杂性的增加,很大程度上是因为 IP 网络的固有变化造成的(丢包补偿和时序恢复)。
数据包接收
TODO
RTP 会话由数据流和控制流组成,在不同的端口上运行(通常数据包在偶数端口上运行,控制数据包在下一个奇数端口上运行)。这意味着接收应用程序为每个会话打开两个套接字:一个用于数据,一个用于控制。因为 RTP 运行在 UDP/IP 之上,所以使用的套接字是标准的 SOCK_DGRAM 套接字,就像类似于 unix 上的 Berkeley sockets API 和 Microsoft 平台上的 Winsock 所提供的那样。
一旦创建了套接字,应用程序就应该准备接收来自网络的数据包,并将它们存储起来以便进一步处理。许多应用程序将其实现成一个循环,反复调用 select()来接收包 -- 例如:
fd_data = create_socket(...);
fd_ctrl = create_socket(...);
while (not_done)
{
if (FD_ISSET(fd_data, &rfd))
{
...validate data packet
...process data packet
}
if (FD_ISSET(fd_ctrl, &rfd))
{
...validate control packet
...process control packet
}
}
如第四章《RTP 数据传输协议》和第五章《RTP 控制协议》所述,对数据和控制包进行校验,并按照后面两节所述进行处理。select()操作的超时,通常是根据媒体的帧间隔所配置的。例如,接收 20 毫秒音频数据包的系统需要设置 20 毫秒的超时时间,从而允许其他处理(例如解码接收到的数据包)与到达和播放同步进行,从而导致应用程序每 20 毫秒循环一次。
其他的实现方式可能是事件驱动的,而不是显式的循环,但是基本概念仍然存在:数据包在从网络到达时不断进行验证和处理,并且必须并行进行其他应用程序处理(明确的进行事件分隔或者做为一个单独的线程),应用程序的时间取决于媒体处理的要求。实时操作对于 RTP 接收端至关重要,数据包必须以其到达的速率进行处理,否则会影响接收质量。
数据包的接收
媒体播放过程的第一阶段是从网络获取 RTP 数据包,缓冲这些数据包并进行处理。由于网络容易破坏包间的时序,如图 6.5 所示,当多个包同时达到时,会出现冲突;当没有包到达时,会出现间隔甚至出会出现包无序到达的情况。接收端不知道数据包何时到达,所以它应该准备好接收突发的数据包或以任何顺序接收数据包。
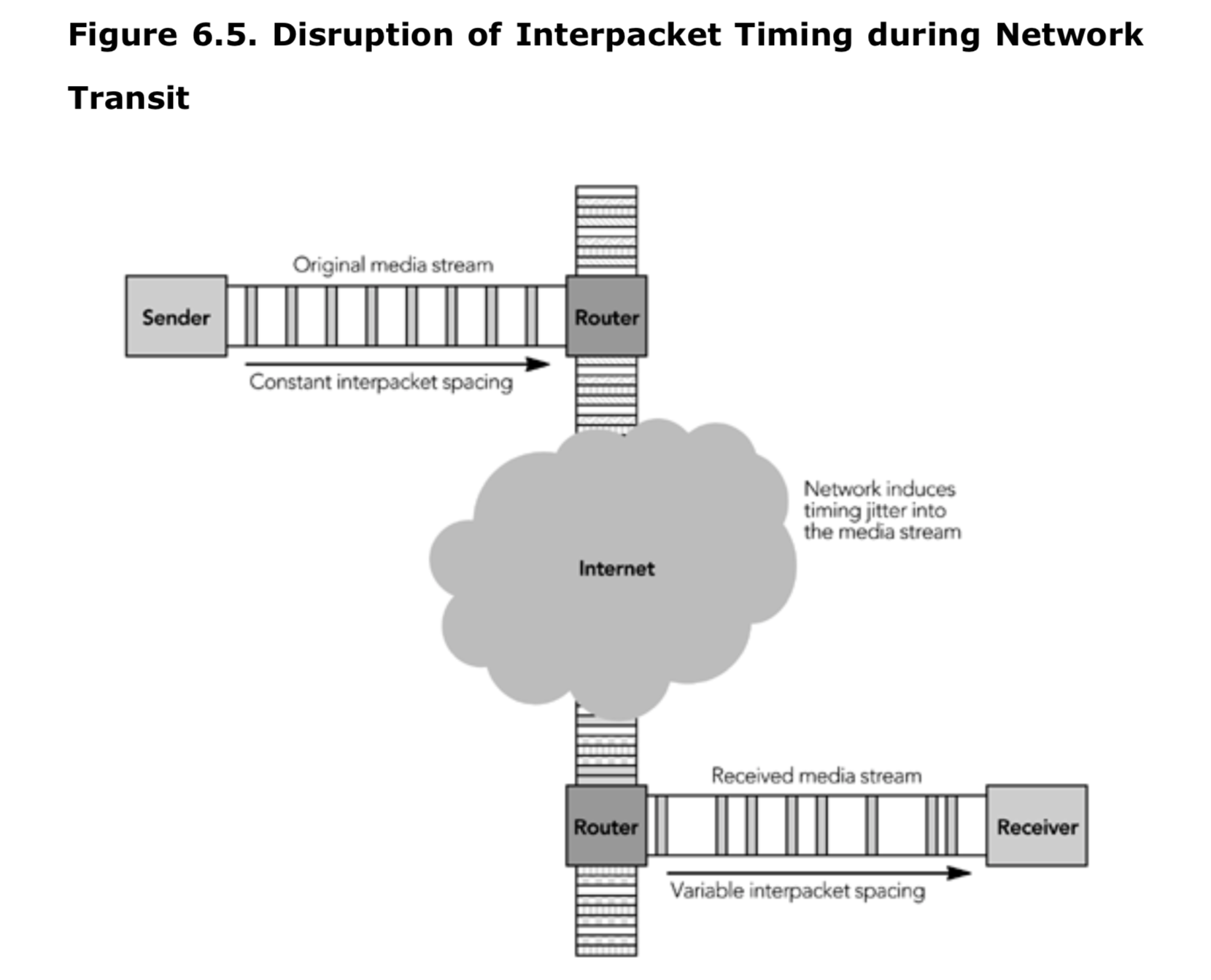
接收到数据包后,将对它们进行正确性校验,记录其到达时间,并按照 RTP 时间戳排序,然后将它们添加到每个发送端的输入队列中,以供以后处理。这些步骤可以将数据包的到达速率与处理和播放进行分隔,从而使得应用可能应对到达速率的变化。图 6.6 显示了数据包接收和播放程序之间的分隔,它们仅由输入队列链接。
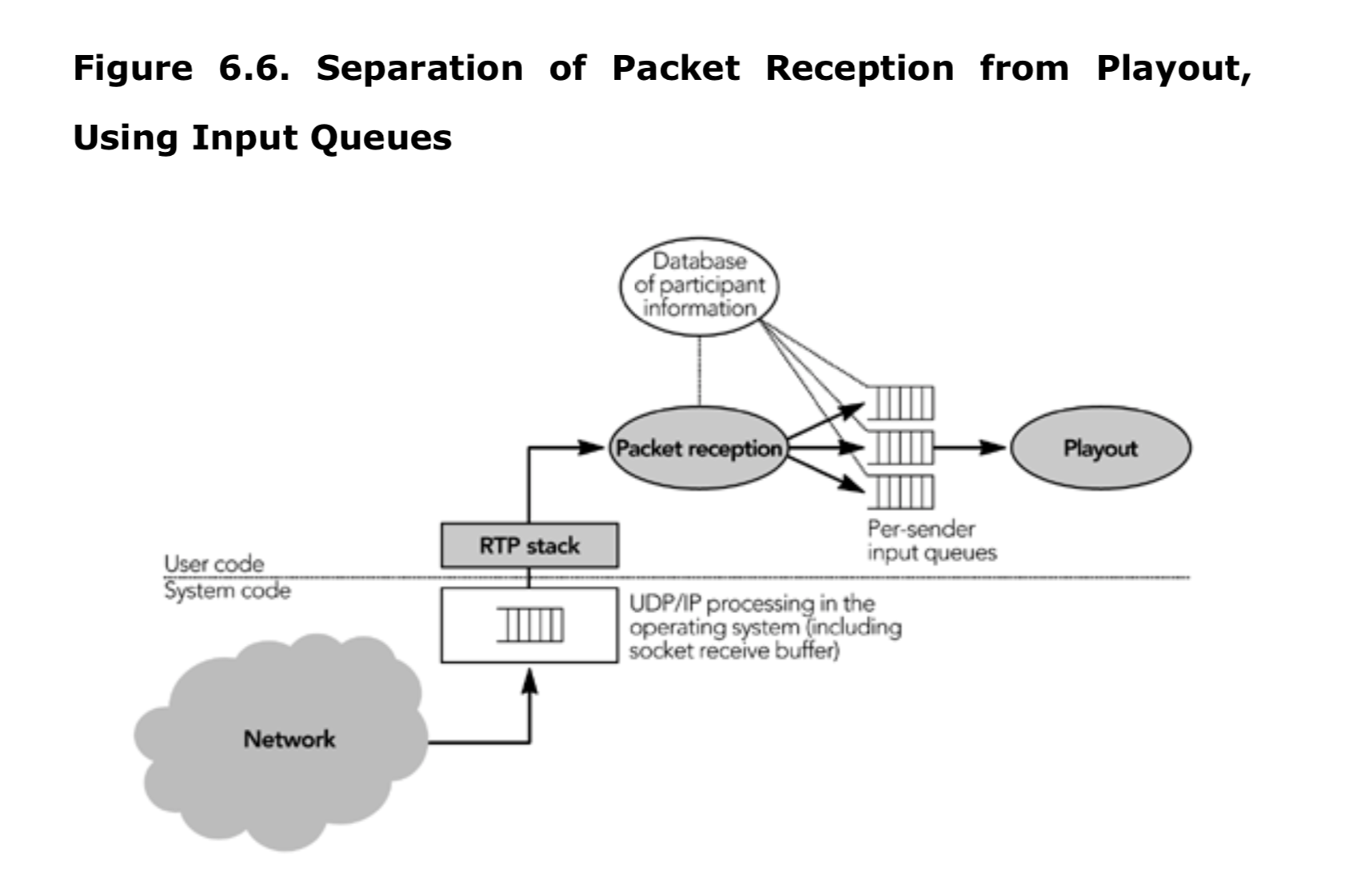
重要的是要存储 RTP 数据包的准确到达时间.M.,以便计算达到间隔抖动。不准确的到达时间测量会造成网络抖动,导致播放延迟增加。到达时间应该根据本地参考时钟.T.来测量,并转换为媒体时钟速率.R.。接收房目前不太可能有这样的时钟,所以,我们通常通过采样参考时钟(通常是系统的时钟)并将其转换为本地时间轴来计算到达时间。
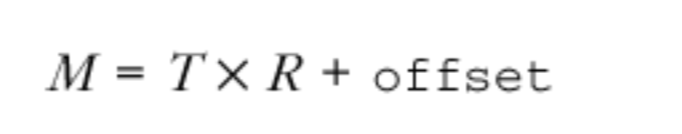
在校正媒体时钟和参考时钟之间的偏差的过程中,使用 offset 从参考时钟映射到媒体的时间线。
如前所述,数据包的处理可以在单线程的应用程序中与数据包接收一起进行时间分割,或者可以在多线程的系统中的单独线程中运行。在时间分段的设计中,单个线程即处理数据包接收又处理播出。在每个循环中,所有未完成的数据包都从套接字中读取并插入到正确的输入队列。数据包根据需要从队列中删除并安排进行播放。如果数据包以突发形式到达,则某些数据可能会保留在其输入队列中,以进行循环多次迭代,具体取决于所需的播出速率和可用的处理能力。
多线程的接收端通常有一个线程等待数据到达的套接字,并将到达的数据包排序正确后输入到队列。其他线程从输入队列中提取数据,并安排对媒体进行解码和播放。线程的异步操作以及输入队列的缓冲,有效地使播放过程与输入速率的短期变化脱钩。
无论选择哪种设计,应用程序通常都不能连续的接收和处理数据包。输入队列适应应用程序内的播放抖动,但是碰到收包程序中延迟怎么办?幸运的是,大多数通用操作系统在中断驱动的基础上处理 UDP/IP 数据包的接收,并且即使在应用程序繁忙的时候,也可以在套接字级别缓冲数据包。此功能在数据包达到应用程序前提供有限的缓冲。默认套接字缓冲区适用于大多数实现,但是,接收高速率流或有大量时间无法处理接收数据的应用程序可能需要增加套接字缓冲区的大小,使其超过默认值(setsocket(fd,SOL_SOCKET,SO_RCVBUF)这个函数在许多操作系统中都存在)。较大的套接字缓冲区适应了数据包接收过程中的各种延迟,应用程序将数据包在套接字缓冲区中花费的时间视为网络中的抖动。应用程序可能会增加它的播放延迟来补偿这种可感知的变化。
接收控制包
在数据包到来的同时,应用程序必须准备接收、校验、处理和发送 RTCP 控制包。RTCP 包中的信息用于维护会话内发送端和接收端的数据库,如第五章《RTP 控制协议》中所讨论的,主要用于参与者校验和识别、适应网络条件和音视频同步。参与者数据库也是挂起参与者特定的输入队列、播放缓冲区和接收端需要的其他状态的好地方。
单线程应用程序通常在其 select()循环中同时包含数据和控制套接字,从而将控制数据包的接收和其他处理交织在一起。多线程的应用程序可以将一个线程用于 RTCP 接收和处理。由于与数据包相比,RTCP 包很少出现,因此它们的处理开销通常比较低,而且对时间要求不是特别严格。但是,记录发送报告(SR)数据包的确切到达时间非常重要,因为这个值在接收端报告(RR)数据包中返回,用于计算往返时间。
当 RTCP 发送端/接收端报告包到达时(描述在特定接收端处看到的接收质量),将存储它们包含的信息。解析 SR/RR 包中的报告块很简单,只要你记住数据是按照网络字节顺序进行排列的,在使用之前必须将其转换为主机的顺序。RTCP 包头中的 count 字段表示有多少报告块;请记住,0 是一个有效值,表示 RTCP 包的发送端没有接收到任何 RTP 数据包。
RTCP 发送端/接收端报告的主要用途是,用于应用程序监视其发送的流的接收情况,如果报告显示接收情况不佳,则可以添加错误保护或降低发送速率来进行补偿。在多发送端会话中,还可以监视其他发送端的质量,就像其他接收端看到的那样;例如,网络操作中心可以监视 SR/RR 数据包,以检查网络是否正常运行。应用程序通常在接收时存储接收质量数据,并定期使用存储的数据来适应其传输。
发送端报告还包含 RTP 媒体时钟和发送端参考时钟之间的映射(用于音视频同步),以及发送数据量的计数。同样,这些信息是按照网络字节顺序排列的,在使用前需要进行转换。如果用于音视频同步的目的,那么需要将其存储下来。
当 RTCP 源描述包到达时,它们包含的信息被存储并可能显示给用户。RTP 规范包含用于解析 SDES 数据包的示例代码(参见规范的附录 A.5)。SDES CNAME(规范名)提供音视频流之间的链接,指示应该在何处做音视频同步。它还用于对来自单个源的多个流进行分组(例如,如果一个参与者有多个摄像头向一个 RTP 会话发送视频),这可能会影响向用户显示媒体的方式。
验证 RTCP 数据包后,它们所包含的信息将添加到参与者数据库中。由于对 RTCP 数据包的有效性检查很强,因此数据库中存在参与者是表明参与者有效的可靠指示。这在验证 RTP 数据包时非常有用:如果以前在 RTCP 数据包中看到过 RTP 数据包中的 SSRC,那么它很可能是一个有效的源。
当接收到 RTCP Bye 包时,参与者数据库中的条目将被标记为稍后删除。如第五章所示,当收到 bye 时,RTP 控制协议不会立即删除条目,而是保留一段时间,以允许任何延迟的数据包到达。(我自己实现使用了一个固定的两秒超时,这个值是否精确不重要,只要它大于经典网络抖动就可以)接收端也要执行定期的清理工作,以便于使不活跃的参与者超时。不要要对每个包执行这个任务,每个 RTCP 的报告间隔一次就足够了。
播放缓冲区
数据包从其输入队列中提取出来,并插入到根据它们的 RTP 时间戳排序的特定于源的播放缓冲区中。帧信息会被保存在播放缓冲区一段时间,以平滑网络引起的时间变化。将数据保存在播出缓冲区中还可以接收分段帧的分段并进行分组,并且可以允许任何纠错数据到达。然后解码帧,隐藏任何剩余的错误,并且为用户做展现。图 6.7 说明了该过程。
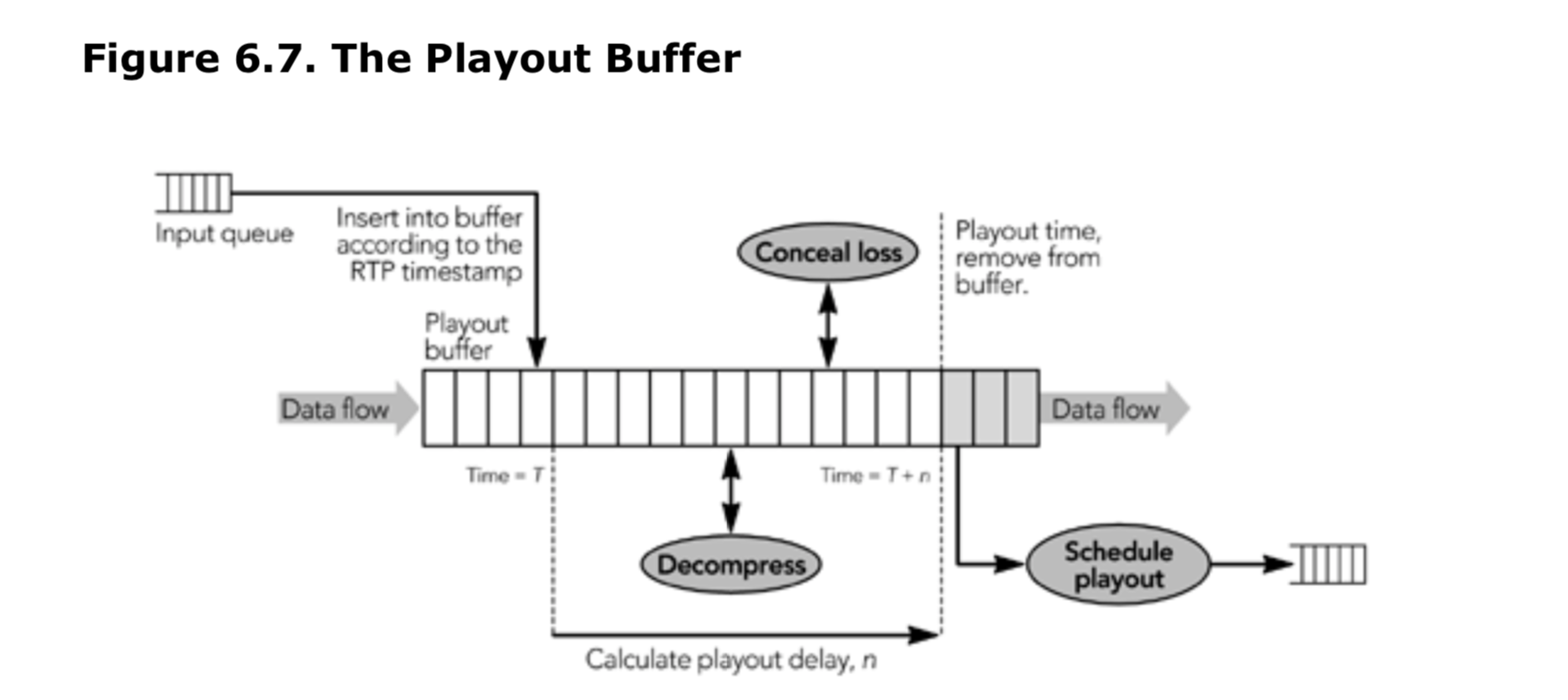
单个的缓冲区可以用来补偿网络时间的变化,并作为解码缓冲区的媒体解码器。也可以分离这些功能:使用单独的缓冲区进行抖动消除和解码。在 RTP 中从来没有严格的分层要求:高效的实现常常应该跨越层的边界混合相关功能,这是一个称为“集成层处理”(integrated layer processing)的概念。
基础操作
播放缓冲区包含一个按时间序列排列的节点链表。每个节点代表一帧媒体数据以及相关的时序信息。每个节点的数据结构包含指向相邻节点的指针、到达时间、RTP 时间戳和帧所需的播放时间,以及指向帧的编码片段(RTP 包接收的数据)和未编码的媒体数据的指针。图 6.8 说明了所涉及的数据结构。
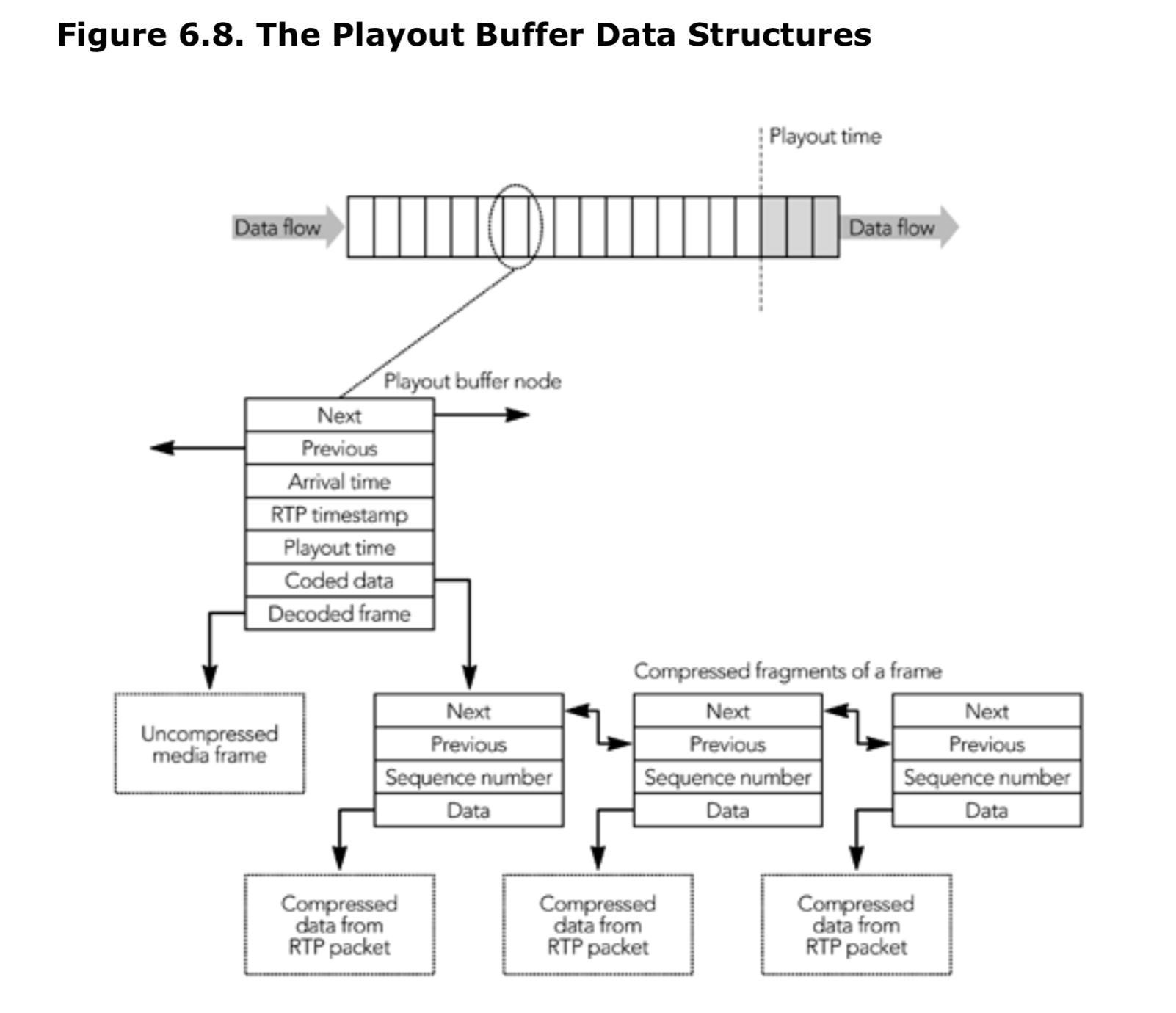
当帧中的第一个 RTP 包到达时,它将从输入队列中删除,并按 RTP 时间戳的顺序放置在播放缓冲区中。这涉及到创建一个新的播放缓冲区节点,该节点被插入到播放缓冲区的链表中。来自最近到达的分组的编码数据从播出缓冲节点被链接,以用于以后的解码。然后计算帧的播放时间,本章稍后将对此进行解释。
新创建的节点驻留在播放缓冲区中,直到达到播放时间为止。在此等待期间,包含帧的其他片段的包,可能到达并从此节点链接。一旦确定已接收到帧的全部片段,就会调用解码器,并从播放缓冲区节点链接封装未编码的帧。确定一个完整的帧已收到取决于编码器:
- 音频编码器通常不分段帧,每帧只有一个包(mp3 是常见的例外)
- 视频编解码器通常为每个视频帧封装多个包,并设置 RTP 标记位来指示包含最后一个分段的 RTP 包。
接收到设置了标记位的视频数据包并不一定意味着已经接收到完整的帧,因为数据包可能会在传输过程中丢失或重新排序。相反,它给出了帧的最高 RTP 序列号。一旦接收到所有具有相同时间戳但序列号较低的 RTP 数据包,该帧即告完成。如果接收到带有前一帧标记位的数据包,则可以轻松确定该帧是否完整。如果该数据包丢失(如没有收到标记位却发生了时间戳改变),并且根据序列号仅丢失一个数据包,则丢失的包后的第一个数据包是帧的第一个数据包。如果丢失了多个数据包,通常就无法判断这些数据包是属于新帧还是前一帧(媒体格式的知识在某些情况下可以确定帧边界,但是这种能力取决于特定的编解码器和有效负载格式)。
何时调用解码器取决于接收端,而不是有 RTP 指定。帧可以在到达时立即解码,或者一直编码到最后一刻。这两种选择,取决于处理的周期和未编码帧的存储空间的相对可用性,并且可能取决于接收端对未来资源可用性的估计。例如,如果接收端知道帧的索引已经到期,并且很快就要忙起来,那么它可能希望尽早解码数据。
何时调用解码器的决定取决于接收端,而不是由 RTP 指定。帧一到达就可以解码,或者保持编码直到最后一刻。选择取决于未编码帧的处理周期和存储空间的相对可用性,并且可能取决于接收端对未来资源可用性的估计。 例如,如果接收端知道索引帧到期并且它自己不久将忙起来,则它可能希望提早解码数据。
最终,一帧的播放时间到了,帧将排队等待播放,如本章后面的《解码,混流和播放》部分所述。 如果尚未解码该帧,则此时即使某些分段丢失,接收端也必须尽最大努力解码该帧,因为这是在需要该帧之前的最后机会。这也是可以调用错误隐藏(请参阅第 8 章)以隐藏任何未纠正的数据包丢失的时间。
一旦帧被播放完,相应的播放缓冲区节点,及其关联的数据应该被销毁或回收。但是,如果使用了错误隐藏,则最好将此过程延迟到周围的帧也完成之后,因为链接的媒体数据可能对隐藏操作有用。
对于延迟到达的数据包,以及与错过其播放点的帧相对应的数据包,应该丢弃。包的及时性可以通过比较它的 RTP 时间戳和播放缓冲区中最老的包的时间戳来确定(注意,比较应该使用 32bit 的模运算,以允许时间戳的翻转)。选择播放延迟显然是可取的,这样延迟的包就比较少,应用程序应该监视延迟包的数量,并准备调整它们的播放延迟来响应。延迟的数据包表示不适当的播放延迟,通常是由发送端和接受者的时钟之间的网络延迟或偏移(skew)造成的。
对播放缓冲区的操作需要在保真度和延迟之间做权衡:应用程序必须确定它可以接受的最大播放延迟,而这又决定了及时到达要播放的数据包的比例。为交互式使用而设计的系统 -- 例如,视频会议或电话 -- 必须尽量减少播放延迟,因为它无法承受缓冲带来的延迟。对人类感知能力的研究指出,交互使用的最大可容忍的往返时间限制在 300ms 左右。如果系统是对称的,则该限制意味着只有 150 毫秒的端到端延迟,包括网络传输时间和缓冲延迟。然而,非交互式的系统,如流视频、电视或广播,可能允许播放的缓冲区增长到几秒,从而使非交互式系统能更好的处理包到达的时间。
播放时序的计算
设计 RTP 播放缓冲区的最大难点是确定播放延迟,在播放之前,数据包应该在缓冲区中停留多长时间?答案取决于多种因素:
- 接收帧的第一个和最后一个数据包之间的延迟
- 接收任何纠错数据包之前的延迟(见第九章《错误恢复》)
- 由于网络抖动和路由更改导致的数据包间的时序变化
- 发送端和接收端之间的相对时钟偏移(skew)
- 应用程序的端到端之间延迟预测,以及接收质量和延迟的相对重要性。
受应用程序控制的因素,包括帧中数据包的间隔以及媒体数据和任何纠错数据包之间的延迟,而这两者均由发送端控制。这些因素对延迟计算的影响将在本章后面的发送端行为补偿一节中讨论。
应用程序无法控制网络的行为,以及发送端和接收端时钟的准确性和稳定性。以图 6.9 为例,它显示了追踪 RTP 音频包的包传输时间和接收时间之间的关系。发送时钟和接收时钟的运行速度是一样的,这张图的斜率应该正好是 45 度。在实践中,发送端和接收端时钟通常是不同步的,以略微差异的速率运行。对于图 6.9 中,发送端时钟的运行速度快于接收端时钟,因此图中的斜率小于 45 度(图 6.9 是一个极端的例子,为了更容易看到效果,坡度通常更接近 45 度)。本章后面的“对时钟倾斜的补偿”一节解释了如何对不同的时钟进行校正。
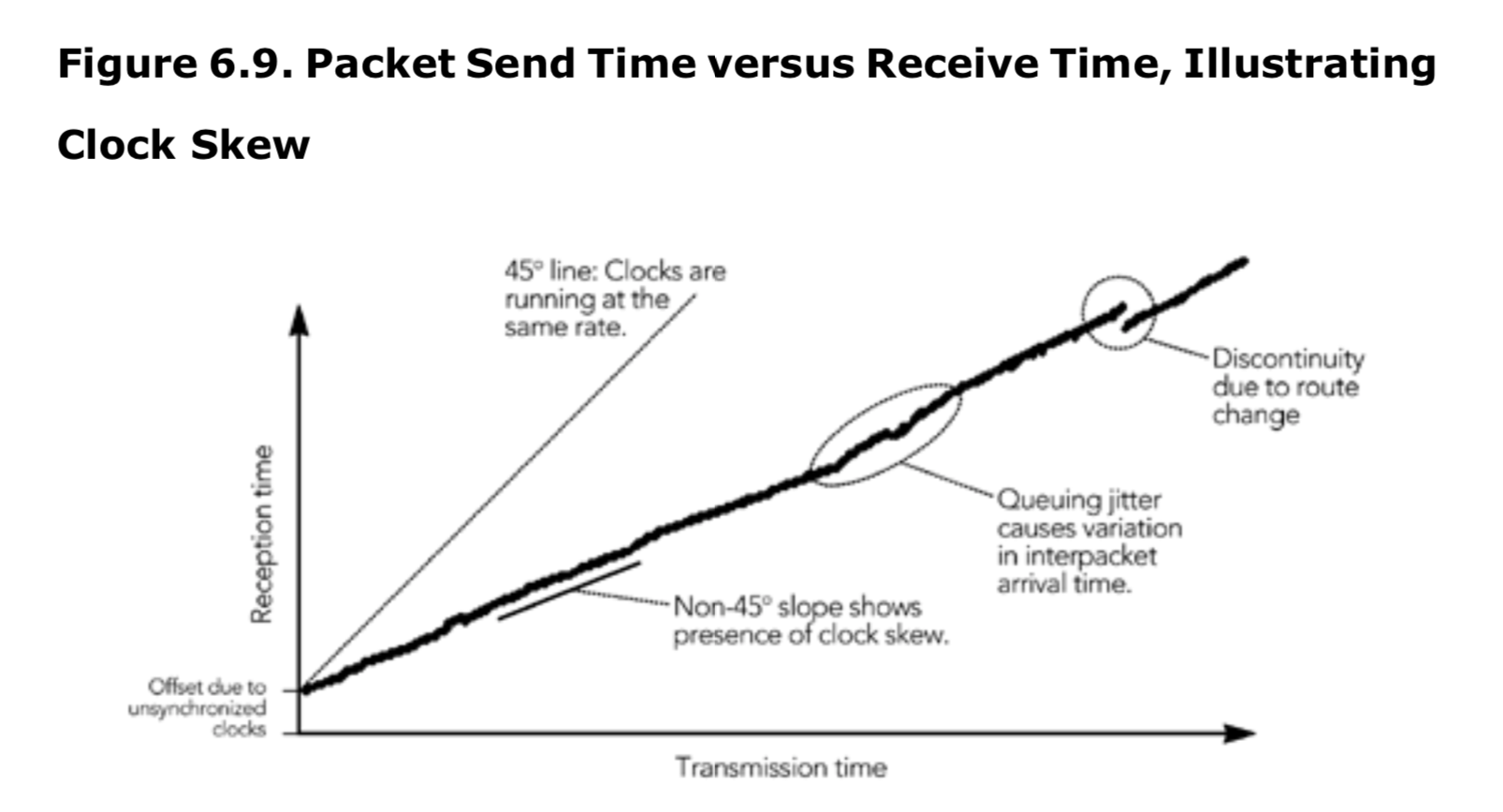
如果包网络传输时间恒定,图 6.9 中将生成一条直线。然后由于排队延迟的变化,数据包间通常会在的间隔中引起一些网络抖动,这在图中可以看出是与直线图的偏差。该图还显示了不连续性,这是由于网络传输时间的阶跃变化而引起的,很可能是由于网络中的路由变化所导致的。第二章《分组网络上的音视频通信》中,更详细的讨论了抖动的影响,本章后面“抖动补偿”一节解释了如何纠正这些问题。在路由变化补偿和包重排序部分讨论了对更极端变化的校正。
最后考虑的是应用程序的端到端延迟预估。这主要是个人因素问题:应用程序的用户可接受的最大端到端延迟是多少?在去除网络传输时间之后,还需要多长时间才能平滑播放缓冲区?正如预期的那样,缓冲可用的时间量,确实会影响播放缓冲区的设计。标题为《抖动补偿》的部分进一步讨论了这个主题。
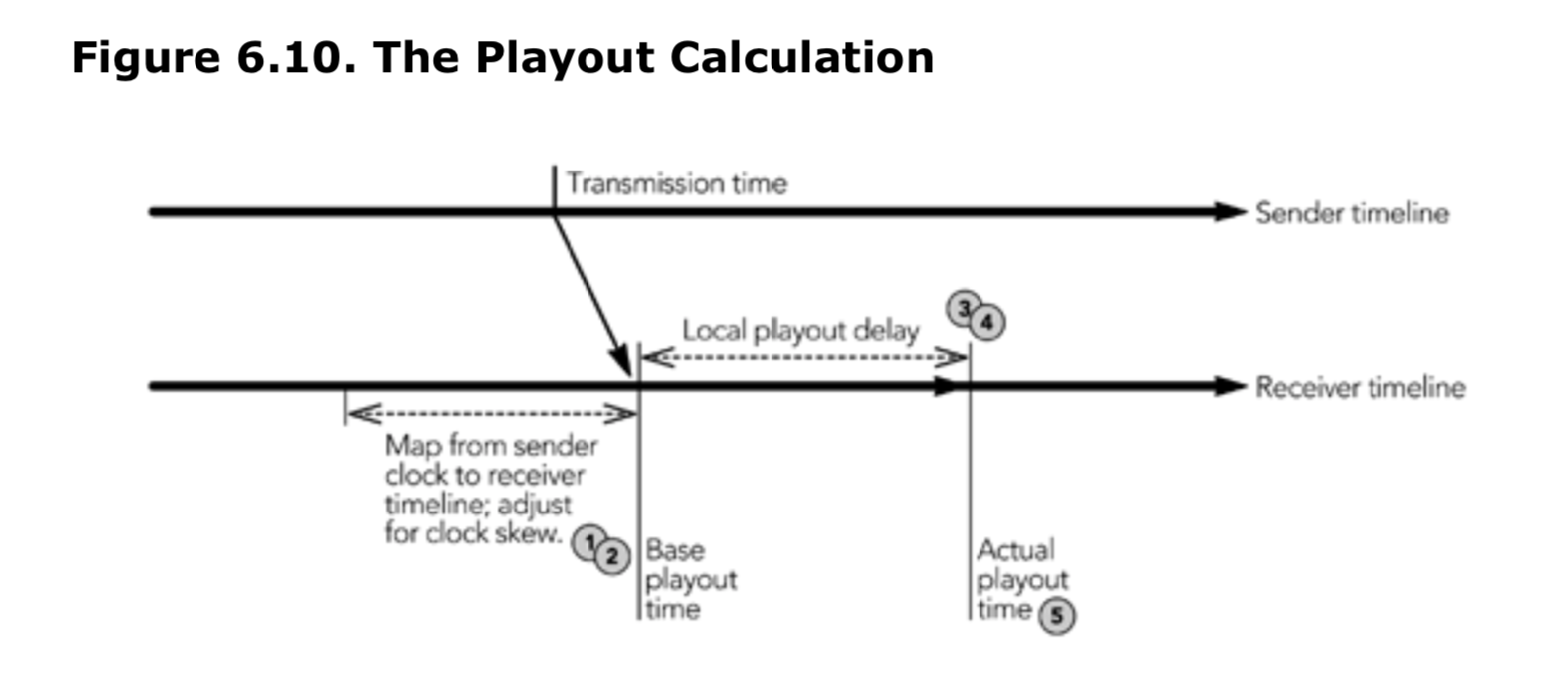
在决定每一帧的播放时间的时候,接收端应该考虑这些因素。对播放的计算步骤如下:
- 发送端的时间轴映射到本地播放时间轴,以补偿发送端和接收端时钟之间的相对偏移,以导出播放时间计算的基准时间(请参考本章后面的映射到本地时间轴)。
- 如果有必要,接受者可以通过添加一个偏移补偿偏移来补偿相对发送端的时钟,该偏移会定期校准基准时间(参见时钟偏移补偿)。
- 本地时间轴上的播放延迟是根据播放延迟中与发送端相关的部分(参考“发送端行为的补偿”)和与抖动相关的部分(请参见“抖动补偿”)计算的。
- 如果路由发生了变化(参见路由变化的补偿),如果包被重新排序(参见排序的补偿),如果选择的播放延迟导致帧重叠,或者相应媒体中其他的变化(参见调整播放点),则会调整播放延迟。
- 最后,将播放延迟添加到基准时间中,以获得帧的实际播放时间。
图 6.10 说明了计算的过程,并记录了此过程的步骤。下面部分给出了每个阶段的详细信息。
本地时间轴映射
播放时间计算的第一阶段是通过将发送端和接收端时钟之间的相对偏移添加到 RTP 时间戳,将发送端的时间轴(以 RTP 时间戳表示)映射到接收端有意义的时间轴。
为了计算相对偏移量,接收端需要以相同的单位计算第 n 个包的 RTP 时间戳 与该包的到达时间
与该包的到达时间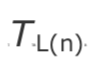 之间的差值 d(n):
之间的差值 d(n):
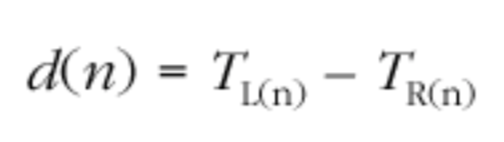
这个差值包含一个常数因子,设置这个常数因子是因为发送端和接受者的时钟是在不同的时间用不同的随机值初始化的,也是因为在发送端处的数据准备时间而引起的延迟可变,也是因为网络传输时间最短而导致的常数因子,更是因为网络时序抖动引起的可变延迟以及由于时钟偏斜引起的速率差。
这个差值 d(n)包括一个常数因数,因为发送端和接收端时钟在不同的时间使用不同的随机值进行初始化;由于在发送端处的数据准备时间而导致的可变延迟;由于最小网络传输时间而导致的常数;由于网络时序抖动以及由于时钟偏移引起的速率差异。差值是一个 32bit 无符号整数,就像计算它的时间戳一样。 并且由于发送端和接收端时钟未同步,因此它可以具有任何 32bit 值。
在每个数据包到达时计算差值,并且接收端跟踪其最小观测值以获得相对偏移:
由于时钟偏移导致 和
和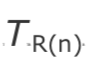 之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
根据接收端的时间轴,偏移量用于计算基本的播放点:
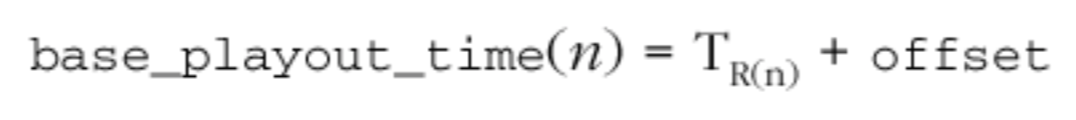
这是对播出时间的初始预估,并应用了其他因素来补偿时钟偏斜(skew)以及抖动等。
时钟偏移(skew)补偿
RTP 有效负载格式定义了媒体流的标准时钟速率,但是对时钟的稳定性和准确性没有任何要求。发送端和接收端的时钟通常以稍微不同的速率运行,从而迫使接收端对变化进行补偿。数据包的传输时间与接收时间的关系图,如图 6.9 所示。如果曲线的斜率正好是 45 度,那么时钟的频率是一样的,偏移是由发送端和接收端之间的时钟倾斜造成的。
接收端必须检测时钟偏移的存在,预估其大小,并调整播放点进行补偿。补偿策略有两种,一种是调整接收时钟以匹配发送时钟,另一种是定期调整播放缓冲区占用率,用以做重新校准。
后一种方法接受偏移,并通过插入或删除数据来定期重新对齐播出缓冲区。 如果发送端速度更快,则接收端最终将不得不丢弃一些数据以使时钟对齐,否则其播出缓冲区将溢出。如果发送端速度较慢,则接收端最终将用尽所有媒体来播放,并且必须合成一些数据以填补剩余的空白。时钟偏移的大小决定了播放点调整的频率,因此会导致质量下降。
或者,如果接收端时钟速率比较容易调整,则有可能将其速率调整为与发送器速率完全匹配,而无需重新设置播放缓冲区。这种方法可以提供更高的质量,因为永远不会由于时钟偏移而丢弃数据,但是它可能需要不常见的硬件支持(使用音频的系统可能能够使用软件重新采样以匹配所需的速率)。
预估时钟偏移的大小,最初看起来是一个简单的问题,观察发送端时钟的速率 -- RTP 时间戳 -- 并与本地时钟进行比较。如果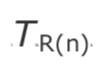 是接收到的第 n 个数据包的 RTP 时间戳,
是接收到的第 n 个数据包的 RTP 时间戳,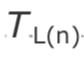 是当时的本地时钟的值,那么时钟偏移的预估如下:
是当时的本地时钟的值,那么时钟偏移的预估如下:
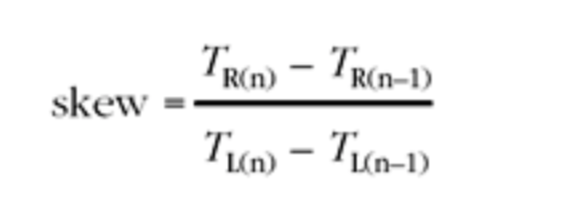
偏移小于 1 表示发送端比接收端慢,而偏移大于 1 表示发送端时钟比接收端快。不幸的是,网络定时抖动的存在意味着这种简单的估计是不够的。它会直接受抖动引起的数据包间隔变化的影响。接收端必须查看数据包到达速率的长期变化,以得出潜在时钟偏移的估计值,从而消除抖动的影响。
根据所需的准确性和对抖动的敏感性,有许多可能的算法可用于管理时钟偏移。在下面的讨论中,我将介绍一种简单的方法来预估和补偿时钟偏移,这种方法已被证明适用于 VOIP,并且给出了针对要求更高的应用的算法的指南。
对时钟偏移的管理方法是,持续监控平均网络传输延迟,并将其与主动延迟预估进行比较。有效延迟预估和测得的平均延迟之间的差距越大,越表示了时钟倾斜的存在,这最终将导致接收端调整播放。当每个包到达时,接受方根据包的接收时间以及其 RTP 时间戳计算 n 个数据包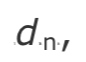 的瞬时单向延迟:
的瞬时单向延迟:
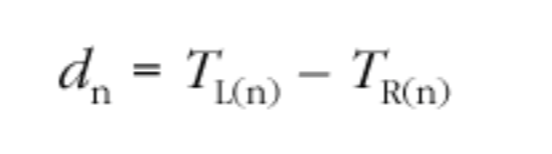
在接收到第一个数据包时,接收端设置活动延迟为 E = d0,预估平均延迟为 D0 = d0。对于每个后续的数据包,平均延迟预估的值 Dn 将通过指数加权移动平均值(exponentially weighted moving average)进行更新:
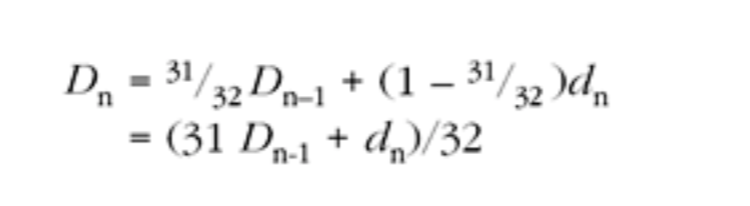
该因子控制平均过程,数值接近于 1,从而使平均值对短期的波动不那么敏感。注意,此计算类似于预估抖动的计算,但是,它保留了变化的符号(sign of the variation),并使用选择的时间常数,来采集长期变化和减少对短期抖动的响应。
将平均单向延迟 Dn 与主动延迟预估 E 进行比较,以用来预估自上次预估以来的差异:
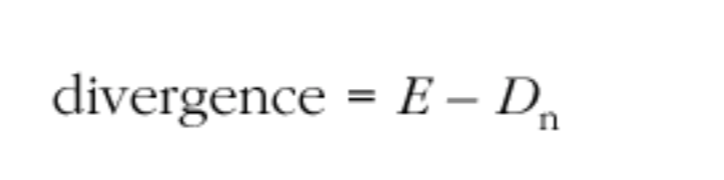
如果发送端时钟和接收端时钟同步,则差异(divergence)将趋近于 0,只会由于网络抖动而产生很小的变化。如果时钟是偏移的,那么它的差异将增加或者减少,直到超过预定的阀值,从而使接收端采取补偿措施。这个阈值,取决于抖动以及编码器和一组可能的适配点(possible adaptation points)。它必须足够大,以避免由于抖动而造成的错误调整,并且应选择适当的位置,使得调整所能引起的不连续性很容易被掩盖。通常单个帧间隔是合适的,这意味着插入或删除整个编解码器的帧。
补偿包括增加或减少播放缓冲区,如本章后面的“自适应播放点”一节所述。播放点可以根据 RTP 时间戳单元的差异做变化(对于音频,差异通常给出要添加或删除的样本数量)。在补偿偏移之后,接收端将活动预估值 E,重置为等于当前延迟预估的值 Dn,在此过程中差异(divergence)重置为 0(此时还将重置 base_play-out_time(n) 的预估值).
在类 C 的伪代码中,当接收到每个包时,执行的算法是这样的:
adjustment_due_to_skew(rtp_packet p, uint32_t curr_time)
{
static int first_time = 1;
static uint32_t delay_estimate;
static uint32_t active_delay;
uint32_t adjustment = 0; uint32_t d_n = p->ts – curr_time;
if (first_time)
{
first_time = 0;
delay_estimate = d_n;
active_delay = d_n;
}
else
{
delay_estimate = (31 * delay_estimate + d_n)/32;
}
if (active_delay – delay_estimate > SKEW_THRESHOLD)
{
// Sender is slow compared to receiver adjustment =SKEW_THRESHOLD; active_delay = delay_estimate;
}
if (active_delay – delay_estimate < -SKEW_THRESHOLD)
{
// Sender is fast compared to receiver adjustment =-SKEW_THRESHOLD; active_delay = delay_estimate;
}
// Adjustment will be 0, SKEW_THRESHOLD, or –SKEW_THRESHOLD. It is // appropriate that SKEW_THRESHOLD equals the framing interval. return adjustment;
}
该算法假设抖动分布是对称的,任何系统偏差都是由时钟偏移引起的。如果偏移值的分布是由时钟偏移以外的原因而不对称的,那么这种算法将导致伪偏移自适应。网络传输时间的短期波动也可能使算法无法描述真正的抖动,接收端将网络抖动视为时钟偏移并调整其播放点。偏移补偿算法最终会自我纠正,不能如何,我们都需要适配网络抖动。
这里描述的偏移补偿的另一个假设是,希望对播放点进行逐步调整 -- 例如,一次添加或删除一个完整的帧 -- 同时隐藏不连续的,就好像丢失了一个包一样。许多编解码器 -- 特别是基于帧的语音编解码器 -- 这是适当的行为,因为编解码器经过优化以隐藏丢失的帧,而偏移补偿可以利用这种能力,只要小心地添加或删除不重要的、通常是低能量(low-energy)的帧。然而,在某些情况下,更平滑地自适应是可取的,可能一次插入一个样本。
如果需要更平滑的自适应,Moon 等人的算法可能更合适,虽然它更复杂,对状态维护的要求也相应更高。他们的方法的基础是在观测到的单向延迟与时间的关系图上使用线性规划,以尽可能在所有数据点下拟合一条最接近数据点的线。一种等效的方法是在图 6.9 所示的数据点下获得一条最佳的拟合直线,并使用它来预估直线的斜率,从而预估时钟的倾斜。如果偏差是恒定的,则这个算法会更准确,但是显然具有更高的开销,因为它要求接收端保持点的历史记录,并执行昂贵的线性拟合算法。但是,如果有足够长的测量间隔,它可以获得非常精确的偏移测量。
长时间运行的应用程序应考虑到偏移是不稳定的,并且其会根据外部的影响而变化。例如,温度的变化会影响晶振的频率,并导致时钟频率的变化以及发送端和接收端之间的偏移。非平稳时钟偏移可能会使使用长期测量的某些算法(例如 Moon 等人的算法)感到困惑。 其他算法,例如前面描述的 Hodson 等人的算法,则在较短的时间尺度上工作并定期重新计算偏移,因此它们对变化具有鲁棒性。
在选择时钟偏移估计算法时,重要的是考虑播出点将如何变化,并选择具有适当准确度的估计器。例如,使用基于帧的音频编解码器的应用程序,可以通过添加或删除单个帧来进行自适应,因此,测量到最近样本的偏移的估计器可能会过大。本章后面的标题为《适应播放点》的部分将更详细地讨论此问题。
虽然它们超出了本书的范围,但是 NTP 的算法可能也会引起读者的兴趣。对于那些对时钟同步和偏移补偿感兴趣的人,推荐阅读 PFC 1305(PDF 版本,可以从 RFC 编辑器的网站http://www.rfc-editor.org获得,比纯文本的版本可读性要强很多)。
发送端补偿
发送端数据包生成过程的性质,可能以多种方式影响接收端的播放时间计算,从而导致播放缓冲延迟增加。
如果发送端将组成一帧视频的数据包扩展到整个帧间隔,则帧的第一个和最后一个数据包之间将存在延迟,接收端必须缓冲数据包,直到接收到整个帧为止 。 图 6.11 显示了附加的播放延迟 Td 的插入,以确保接收端在所有片段到达之前都不会尝试播放该帧。
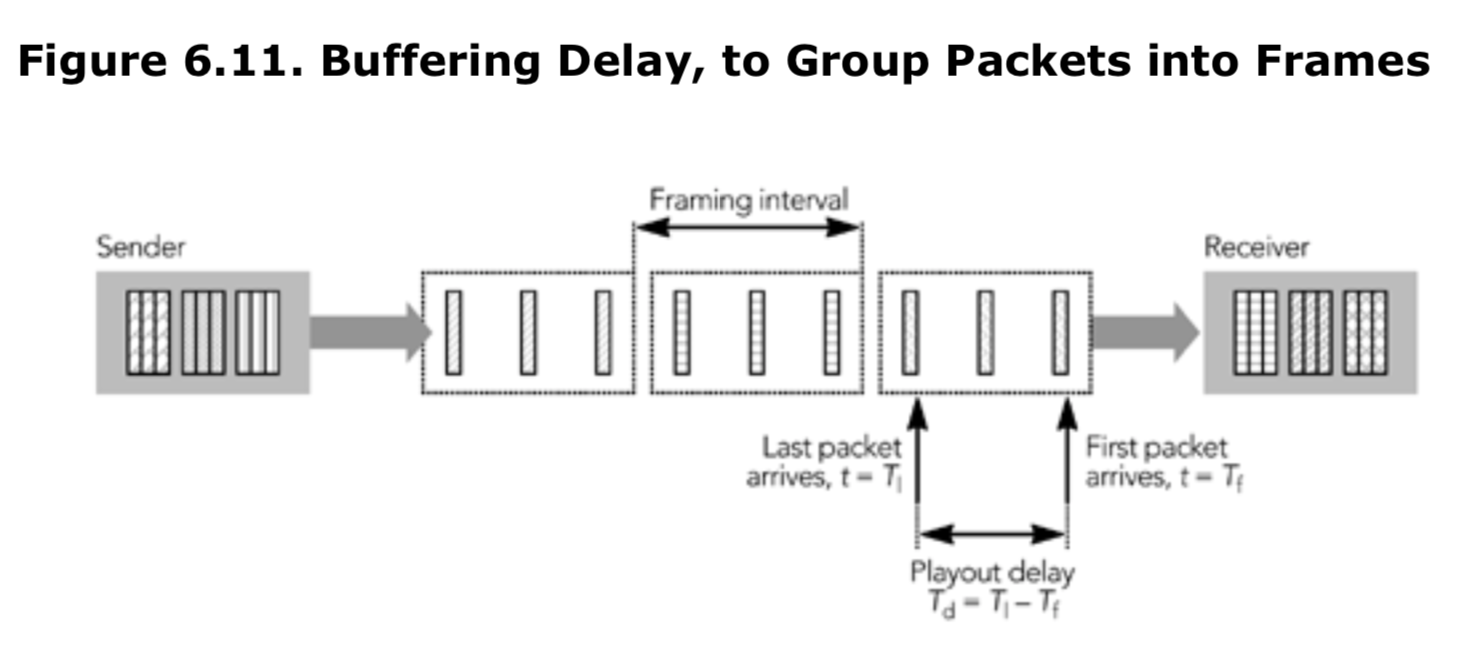
如果知道帧间时序和每帧的数据包数量,则插入额外的延迟很简单。 假设发送端发送数据包的间隔是均匀的,则调整如下:
adjustment_due_to_fragmentation = (packets_per_frame – 1) x (interframe_time / packets_per_frame)
不幸的是,接收端并不总是事先知道这些变量。 例如,在会话建立期间,可能未用声明发送帧率;在会话期间可能会改变帧速率,或改变每帧的数据包数量。 这种变化可能会导致难以排序播放时间,因为尚不清楚需要添加多少延迟才能允许所有分段到达。接收端必须估计所需的播出延迟,并在估计结果不正确时进行调整。
预估的播放补偿可以通过特殊用途的例程来计算,该例程查看分段的到达时间以计算平均分段延迟。幸运的是,这不是必须的。抖动计算起着相同的作用。一个帧的所有包都具有相同的时间戳 -- 表示帧的时间,而不是发送包的时间 -- 因此分段化的帧会导致抖动的出现(接收端无法区分网络中延迟的包和发送端延迟的包)。因此,下一节中讨论的抖动补偿策略可用于预估补偿碎片所需的缓冲延迟量,并且无需考虑播放延迟的主机分量中的分段。
如果发送端使用第 9 章中描述的纠错技术,也会出现类似的问题。为了使纠错包有用,必须延迟播放,以便纠错包及时到达才能使用。 在会话建立期间用信号通知纠错包的存在,并且该信令可以包括足够的信息以允许接收端正确地调整播放缓冲器的大小。 或者,必须从媒体流中推断出正确的播放延迟。 所需的补偿延迟取决于所采用的纠错类型。 三种常见的纠错类型是奇偶校验 FEC(前向纠错)、音频冗余和重传。
第九章讨论的奇偶校验 FEC 方案不修改数据包,并在单独的 RTP 流中发送纠错数据包。纠错包在其 FEC 报头中包含一个位掩码,以标识其保护的包的序号。通过观察掩码,接收端可以确定在数据包中添加的延迟。如果包间隔是恒定的,那么这个延迟就转换为一个时间偏移量,以添加到播放计算中。如果包间隔不是恒定的,接收端必须使用保守的间隔来获得所需的播放延迟。
音频冗余方案在第九章《错误恢复》中讨论,包括冗余包中的时间偏移,该偏移可用于调整播放缓冲区的大小。在通话开始时,冗余音频可在两种模式下使用:发送初始包时不使用冗余头,或使用零长度冗余块发送。如图 6.12 所示,如果初始包中包含零长度冗余块,则调整播放缓冲区的大小会更容易。不幸的是,规范中并没有强制包含这些块,而且实现中可能必须猜测,是否存在适当的播放延迟(单个数据包偏移是最常见的情况,在没有其他信息的情况下进行合理的预估)。一旦确定媒体流使用冗余,就应该将偏移量应用于该流中的所有包,包括在通话开始时发送的没有冗余的包。如果接收到完整的通话开始期(talk spurts)数据而没有冗余,则可以假定发送端已停止冗余传输,并且将来的通话开始期(talk spurts)可以无延迟的播放。
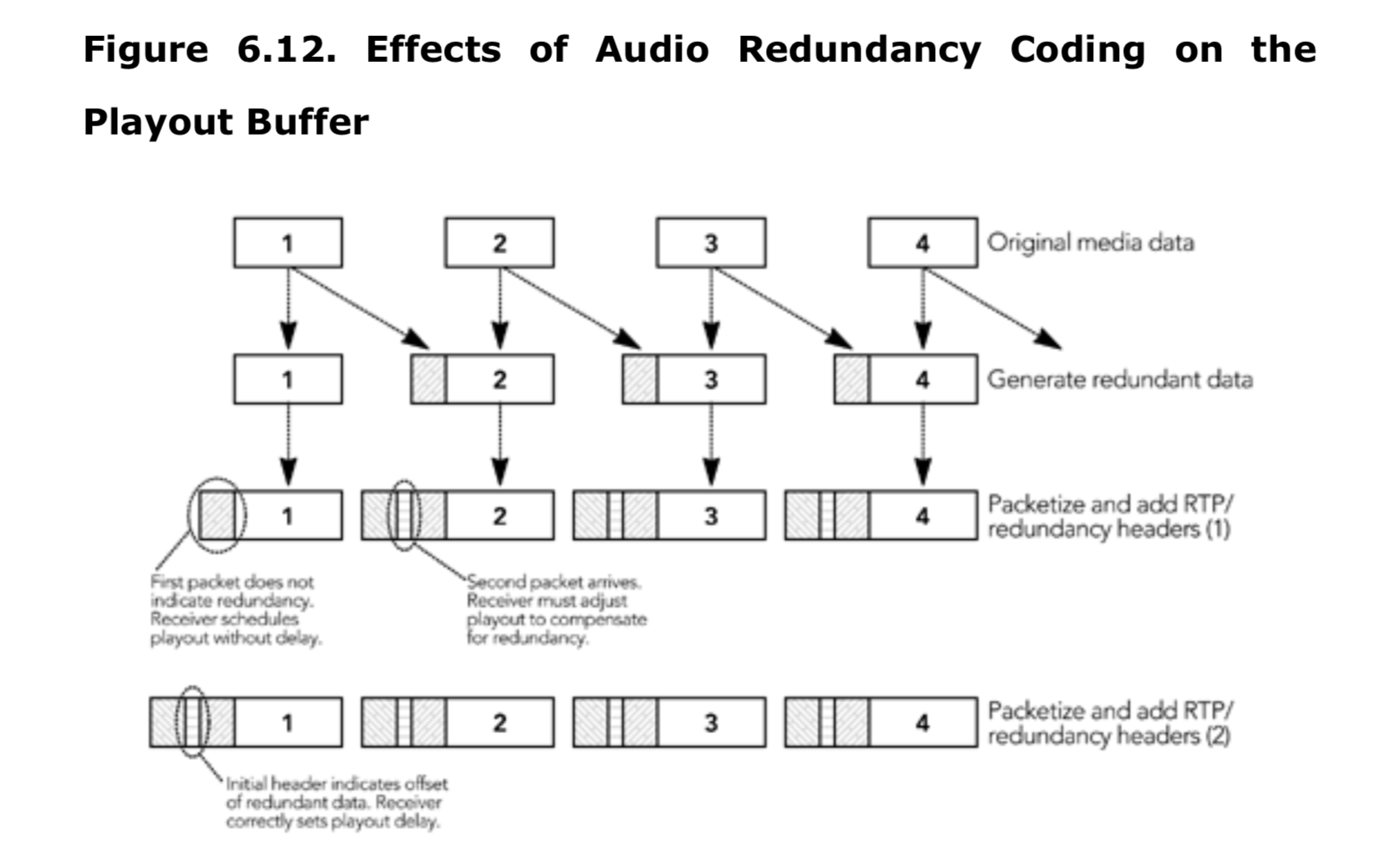
奇偶校验 FEC 或冗余的接收端接收器最初应该选择一个大的播放延迟,以确保到达的任何数据包都被缓冲。当第一个错误恢复包到达时,它将导致接受方减少它的播放延迟,重新安排时间,并播放当前缓冲的包。这个过程避免了由于缓冲延迟的增加而导致的播放间隙,代价是初始包会稍微延迟。
当使用包重传时,播放缓冲区的大小,必须大于发送端和接收端之间的往返时间,以便允许重传请求返回发送端并得到服务。接收端无法知道往返时间,只能发送重传请求并测量相应时间。这并不影响大多数实现,因为重传通常用于非交互应用程序,在这种应用程序中,播放缓冲延迟大于往返时间,但是如果往返时间很大,则可能会出现问题。
无论采用何种纠错方案,发送端都可能产生过量的纠错数据。例如,在发送到多播组(multicast group)时,发送端可能会根据最坏情况的接收端,选择错误恢复码,这对于其他接收端来说太过分了。正如 roseno-berg 等人指出的那样,仅使用错误恢复数据的子集,就可能修复部分损失。在这种情况下,接收端可以选择比所有纠错数据所需的播放延迟更小的播放延迟,而不是等待足够长的时间来修复它所选择的损失。忽略某些纠错数据的决定,完全是由接收端根据其对传输质量的看法做出的。
最后,如果发送端使用了交织媒体流 -- 如第八章所述,错误隐藏 -- 接收端必须在播放计算中考虑这一点,这样才能将交织的数据包按照播放顺序排序。交织参数通常在会话设置期间发出信令,允许接收端选择适当的缓冲延迟。例如,AMR 有效负载格式定义了一个交织参数,该参数可以在 SDP a = fmtp:行中发出信令,表示每个交织组数据包的数量(因此应该插入到播放缓冲区中进行补偿的数据包数量方面的延迟量)。其他支持交织的编解码器应该提供类似的参数。
总而言之,发送端可以通过三种方式影响播放缓冲区:通过对帧进行分段和延迟发送分段,通过使用纠错包或通过交织。 其中的第一个将根据常规的抖动补偿算法进行补偿。 其他要求接收机调整播放缓冲区以进行补偿。这种补偿主要对于使用小的播放缓冲区来减少延迟的交互式应用程序而言是一个问题;而流媒体系统可以简单地设置较大的播放缓冲区。
抖动补偿
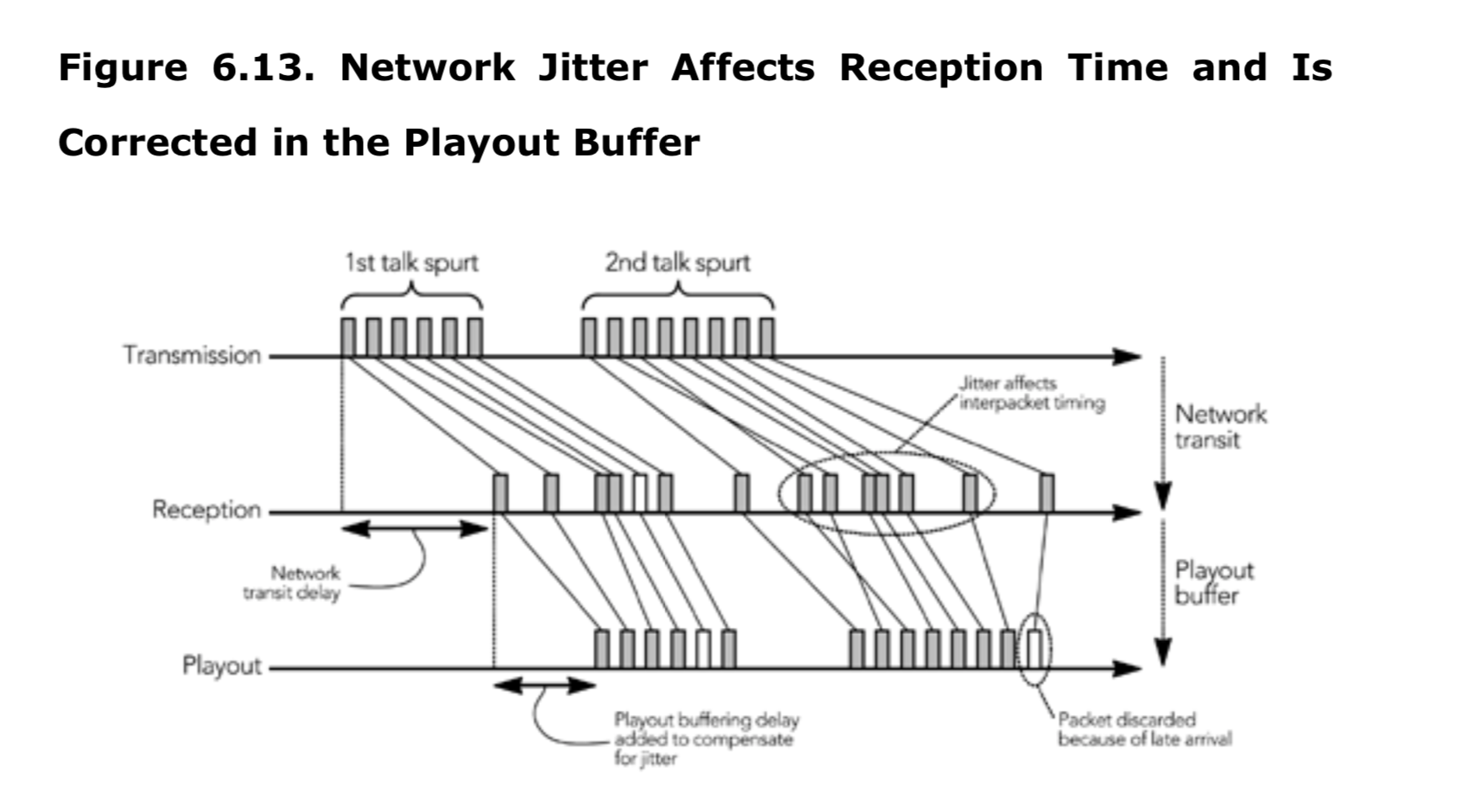
当 RTP 数据包流经真实 IP 网络时,数据包间时序的变化是不可避免的。 这种网络抖动可能很大,接收端必须通过在其播出缓冲区中插入延迟来进行补偿,以便可以处理网络延迟的数据包。延迟过大的数据包在其播放时间过去之后到达,并被丢弃; 选择适当的播出算法后,这种情况很少发生。图 6.13 显示了抖动补偿过程。
抖动补偿延迟的计算,没有标准算法;大多数应用程序都希望自适应的计算播放延迟,并可以根据应用程序类型和网络条件使用不同的算法。为非交互式场景设计的应用程序可以选择一个远远大于预期抖动的补偿延迟;一个适当的值可能是几秒钟。更复杂的是交互情况,在这种情况下,应用程序希望保持输出延迟尽可能小(考虑到特定的网络和分组延迟,数十毫秒的值也是可能的)。为了使播放延迟最小化,有必要研究抖动的特性,并利用这些特性获得最小的适当播放延迟。
在许多情况下,网络引起的抖动基本上是随机的。在这种情况下,包间到达时间(interpacket arrival time)与出现频率(frequency of occurrence)的关系图与图 6.14 的高斯分布有点儿类似。大多数数据包仅受到网络抖动的轻微影响,但是某些异常值则明显延迟或与相邻的数据包粘包(neighboring packet);
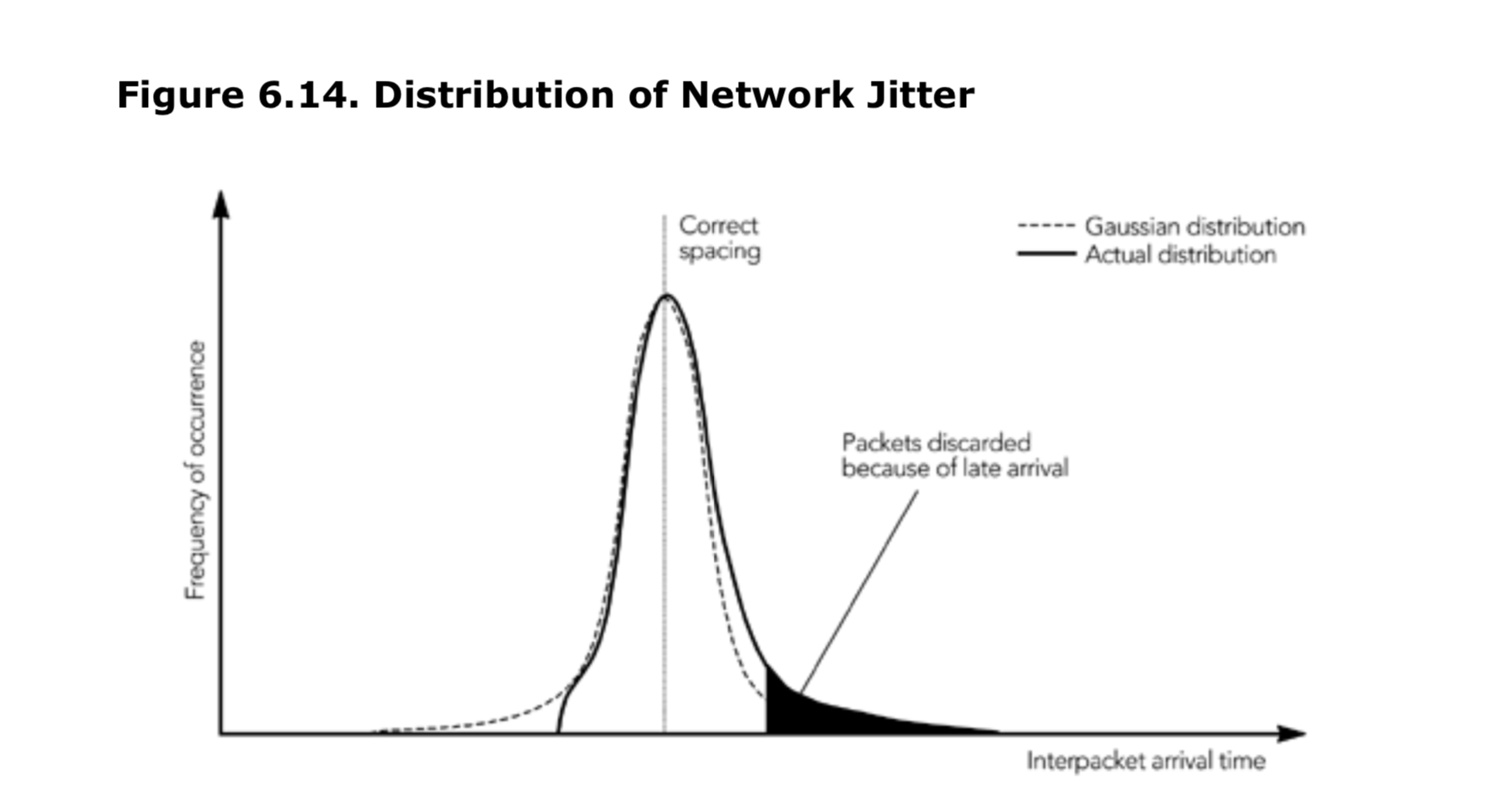
这个近似值有多精确呢?当然,这取决于网络的路径,但是我和 Moon 等人进行的测量表明,在许多情况下,这种方案是近似合理的,尽管现实世界中的数据通常会偏向较大的到达时间,并且具有急剧的最小截止值(如图 6.14 的“实际分布”所示)。这种差异通常不是关键的,因为丢弃区域中的数据包数据量很少。
如果可以假设抖动分布近似于高斯正态分布,那么就很容易推导出合适的播放延迟。抖动的标准差是计算出来的,根据概率论,我们知道 99%以上的正态分布在均值(平均值)标准差的三倍以内。一个实现可能会选择一个等于到达间隔时间标准偏差的三倍的播放延迟,并希望由于延迟到达而丢弃少于 0.5%的数据包。如果此延迟过长,则使用延迟时间为标准差的两倍时,由于延迟到达产生的预期的丢弃率将会少于 2.5%,这也是基于概率论。
我们如何测量标准差?计算用于插入 RTCP 接收端报告的抖动值,跟踪网络传输时间的平均变化,该变化可用于近似标准偏差。根据这些近似值,可以将补偿网络抖动所需的播放延迟预估为特定源 RTCP 抖动预估的三倍。新一帧的播放延迟可以设置为:
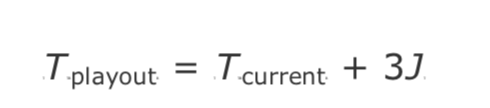
其中 J 为对当前抖动的预估,如第五章 RTP 控制协议所述。Tplayout 的值可以以一种依赖于媒体的方式进行修改,稍后对此讨论。使用此值做为其播放计算的实现,已在一系列实际条件下显示出了良好的性能。
尽管 RTCP 抖动预估提供了一个方便的值,可以用于播放计算中,但如果证明为播出时间提供了可靠的基础,则实现也可以使用备用抖动预估(仍必须在 RTCP RR 中计算并返回标准抖动宇预估)。特别是,有人提出,相位抖动(数据包到达时间与预期时间之间的差值)是对网络时间的更精准的度量,尽管这尚未在广泛部署的实现中进行测试。准确预估交互播放缓冲的抖动是一个难题,与当前的算法相比,还有改进的空间。
抖动分布即取决于流量通过网络时的路径,也取决于共享该路径的其他流量。抖动的主要原因是与其他流量竞争,导致中间路由器的排队时延不同。显然,其他流量中的变化也会影响接收端看到的抖动。因此,接收端应该定期重新计算它们使用的播放缓冲延迟的数量,以防止网络行为发生变化,必要时可以进行调整。接收端应何时调整?这不是一个无关紧要的问题,因为媒体播放时播放延迟的任何变化都会中断播放,导致没有播放内容的间隙,或者迫使接收端丢弃一些数据来弥补丢失的时间。因此,接收端试图限制它们调整其播放点的次数。有以下几个因素可以作为调整的触发因素:
- 由于延迟而丢弃的数据包的比例显著变化
- 接收几个连续的必须因为延迟到达而被丢弃的包(三个连续的数据包是一个合适的阀值)
- 接收到来自长时间不活跃发送端的信息包(10 秒是合适的阀值)
- 网络传输延迟出现尖峰
除了网络传输延迟的峰值外,这些因素应该是不言自明的。如第二章第 2 节的图 2.12 所示,当几个数据包被延迟并突发时,网络有时会导致传输延迟中出现“尖峰”信号。这样的峰值很容易使抖动预估值产生偏差,导致应用程序选择比要求的更大的播放延迟。在许多应用程序中,这种播放延迟的增加是可以接受的,应用程序应该将尖峰视为任何其他形式的抖动,并增加它们的播放延迟来进行补偿。然后,一些应用程序更喜欢增加丢包而不是增加延迟。这些应用程序应该检测延迟尖峰的开始,并在计算播放延迟时,忽略尖峰中的包。
检测延迟尖峰的开始很简单:如果连续数据包之间的延迟突然增加,就可能发送了延迟尖峰。“突然增加”的规模可以有一些解释:Ramjee 等人认为,到达间隔时间统计方差的两倍加上 100 毫秒是一个合适的阈值;我熟悉的另一个实现,用了 375 毫秒的固定阈值(都是使用 8KHz 语音的 ip 语音系统)。
某些媒体事件还会导致连续包之间的延迟增加,不应将其与延迟峰值开始混淆在一起。例如,音频静音抑制将导致在一个通话突发中的最后一个数据包,与下一个通话突发中的第一个数据包之间出现间隙。同样,视频帧速率的变化也会导致包的时序发生变化。在假定数据包间延迟的变化,就意味着出现了一个尖峰之前,应该先检查此类事件。
一旦检测到延迟脉冲,实现时就应该暂停正常的抖动调整,直到脉冲结束。结果,几个包可能会因为延迟到达而被丢弃,但是假设应用程序有严格的延迟边界,且相比于增加播放延迟更倾向于这个结果。
定位一个尖峰的末端比探测它的开始要困难。延迟尖峰的一个关键特征是,在尖峰之后,在发送端均匀间隔的数据包将以突发的形式到达,这意味着每个数据包的传输延迟将逐渐减小,如图 6.15 所示:
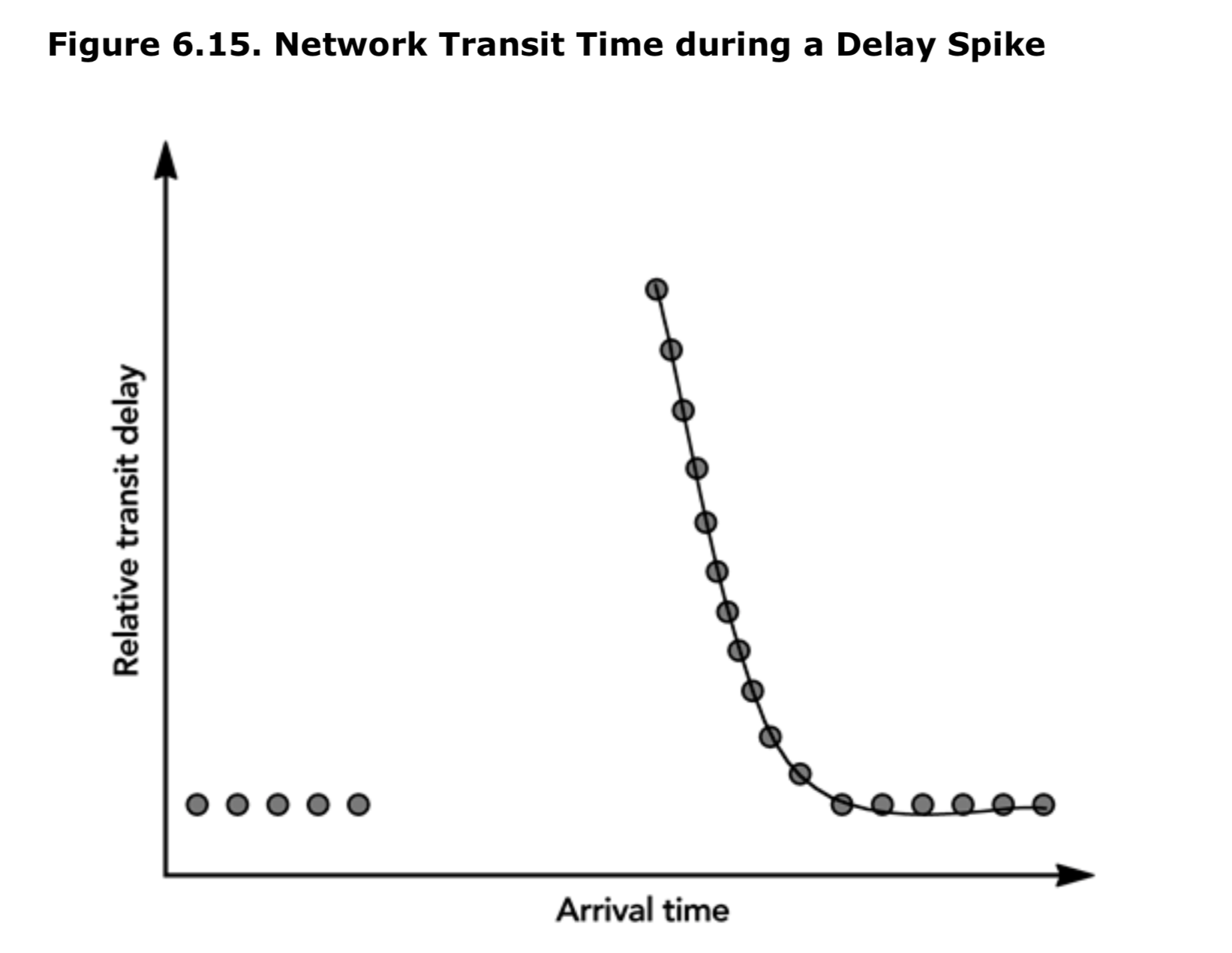
考虑到所有的这些因素,补偿抖动和延迟尖峰影响的播放延迟的伪代码如下:
int
adjustment_due_to_jitter(...)
{
delta_transit = abs(transit – last_transit);
if (delta_transit > SPIKE_THRESHOLD)
{
// A new "delay spike" has started
playout_mode = SPIKE;
spike_var = 0;
adapt = FALSE;
}
else
{
if (playout_mode == SPIKE)
{
// We're within a delay spike; maintain slope estimate
spike_var = spike_var / 2;
delta_var = (abs(transit – last_transit) + abs(transit
last_last_transit))/8;
spike_var = spike_var + delta_var;
if (spike_var < spike_end)
{
// Slope is flat; return to normal operation
playout_mode = NORMAL;
}
adapt = FALSE;
}
else
{
// Normal operation; significant events can cause us to
//adapt the playout
if (consecutive_dropped > DROP_THRESHOLD)
{
// Dropped too many consecutive packets
adapt = TRUE;
}
if ((current_time – last_header_time) > INACTIVE_THRESHOLD)
{
// Silent source restarted; network conditions have
//probably changed
adapt = TRUE;
}
}
}
desired_playout_offset = 3 * jitter
if (adapt)
{
playout_offset = desired_playout_offset;
}
else
{
playout_offset = last_playout_offset;
}
return playout_offset;
}
关键的一点是,抖动补偿在延迟尖峰期间暂停,只有在发生重大事件时,实际播放的时间才会改变。在其他时候,需要将 desired_playout_offset 存储以在特定于媒体的时间恢复(参见标题“调整播出点”的章节)。
路由变更补偿
虽然很少发生,但是,由于链路故障或者拓扑结构发生改变,路由更改就会出现在网络中。如果 RTP 包所采取的的路由发生了变化,它将表现为网络传输时间的突然变化。此更改将会中断播放缓冲区,因为要么数据包到达得太晚而无法播放,要么它们将提前到达并与之前的数据包重叠。
抖动和延迟尖峰补偿算法,应该检测延迟的变化,并调整播放结果对其补偿,但是这种方法可能不是最优的。如果接收端直接观察网络传输时间,并根据较大的变化调整播放时延,就可以进行更快的自适应。例如,如果传输延迟的变化超过当前抖动预估的五倍,则实现时可能调整播放延迟。相对网络传输时间用作抖动计算的一部分,因此这种观察很简单。
对包重新排序的补偿
在极端的情况下,抖动或者路由的更改,可能导致网络中的包被重排序。正如第二章“分组网络上的音视频通信”中所讨论的,这种情况通常很少发生,但是这种情况发生的频度足够引起重视,实现时需要能够补偿它的影响,并平稳的处理包含乱序包的媒体流。
对于正确设计的接收端来说,重新排序应该不是问题,数据包根据它们的 RTP 时间戳插入到播放缓冲区,而不考虑它们到达的顺序。如果播放延迟足够大,则按正确的顺序播放。否则,它们将像任何其他延迟的包一样被丢弃。如果许多包由于重新排序和延迟到达而被丢弃,标准的抖动补偿算法将负责调整播放延迟。
播放点自适应
这是调整播放点的两种基本方法:接收端可以稍微调整每个帧的播放时间,对播放点进行连续的小调整,或者可以从媒体流中插入或删除完整的帧,从而减少播放次数,在必要时在进行少量的大调整。无论如何调整,媒体流都会受到一定程度的干扰。调整的目的是尽量减少这种干扰,这需要了解媒体流方面的知识。我们将分别讨论音频和视频的播放调整策略。
用静音抑制调整音频播放
音频是一种连续的媒体格式,即每个音频帧占用一定的时间,下一帧在完成后立即开始。除非使用静音抑制,否则帧之间是没有间隙的,因此没有合适的时间来适应播放延迟。因此,静音抑制的存在对播放缓冲算法的设计有着重要的影响。
音频是一种连续的媒体格式,这意味着每个音频帧都占用一定的时间,并且下一个音频帧计划在完成后立即开始。 除非使用静音抑制,否则帧之间没有间隙,因此没有合适的时间来适应播放延迟。 因此,静音抑制的存在对音频播放缓冲区算法的设计有重要影响。
对于会话性的语音信号,一个活跃的讲话者将产生持续的几百毫秒的通话尖峰(talk spurts),中间用静音时间隔开。图 6.16 显示了语音信号中语音通话尖峰(talk spurts)的出现以及它们之间的间隙。发送端检测代表了静默期的帧,并对它们进行抑制,否则它们将封装 RTP 数据包。结果是一个带有连续序列号但时间戳跳跃的数据包序列,RTP 时间戳中的跳跃取决于静默期的长度。
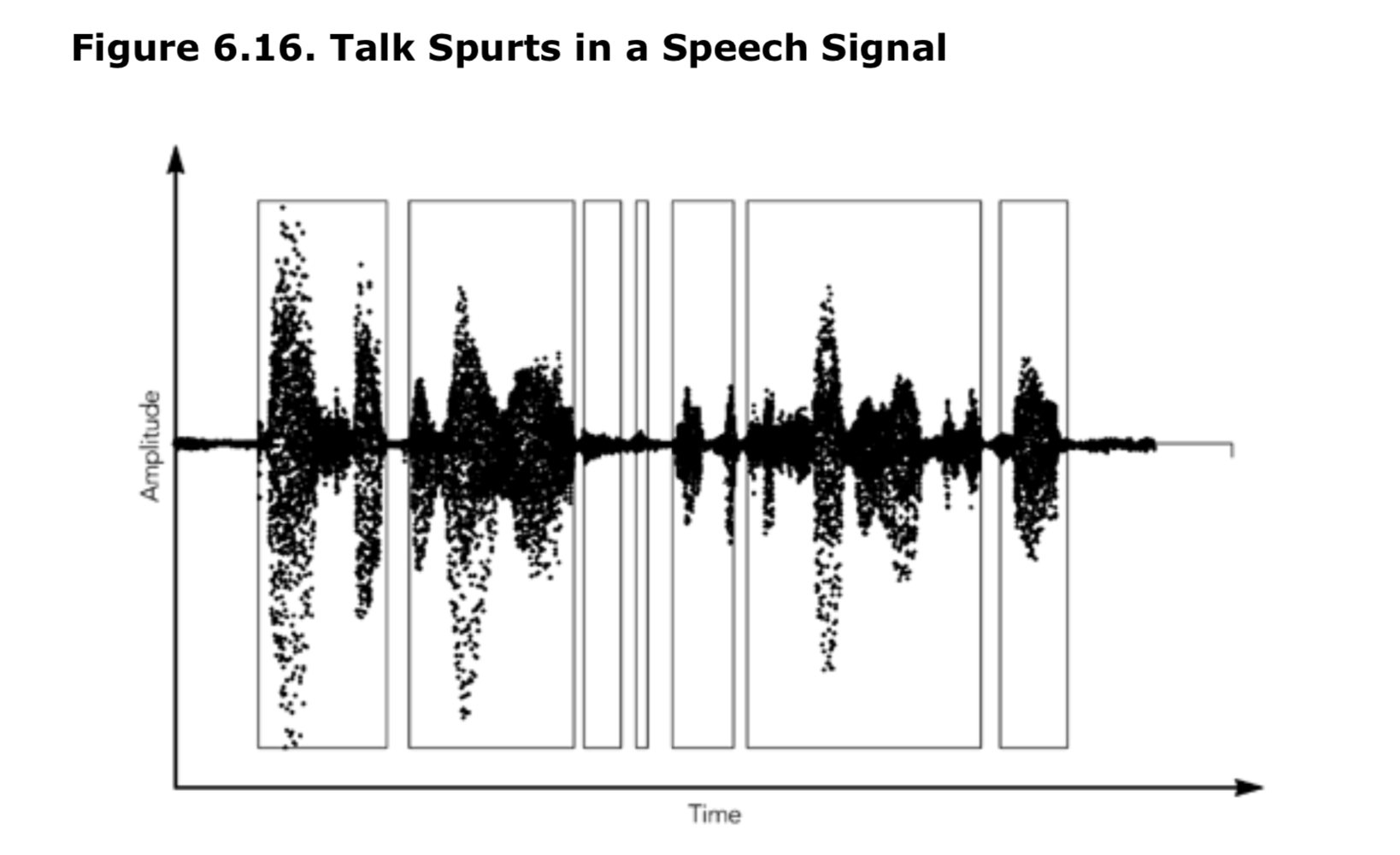
在通话期间使用播放点调整,将在输出中引起可以听见的干扰,但是在通话期之间的静默时段的长度微小变化,将不会被注意到。这是在设计音频工具的播放算法时要记住的关键点:如果可能,只在静默期调整播放点。
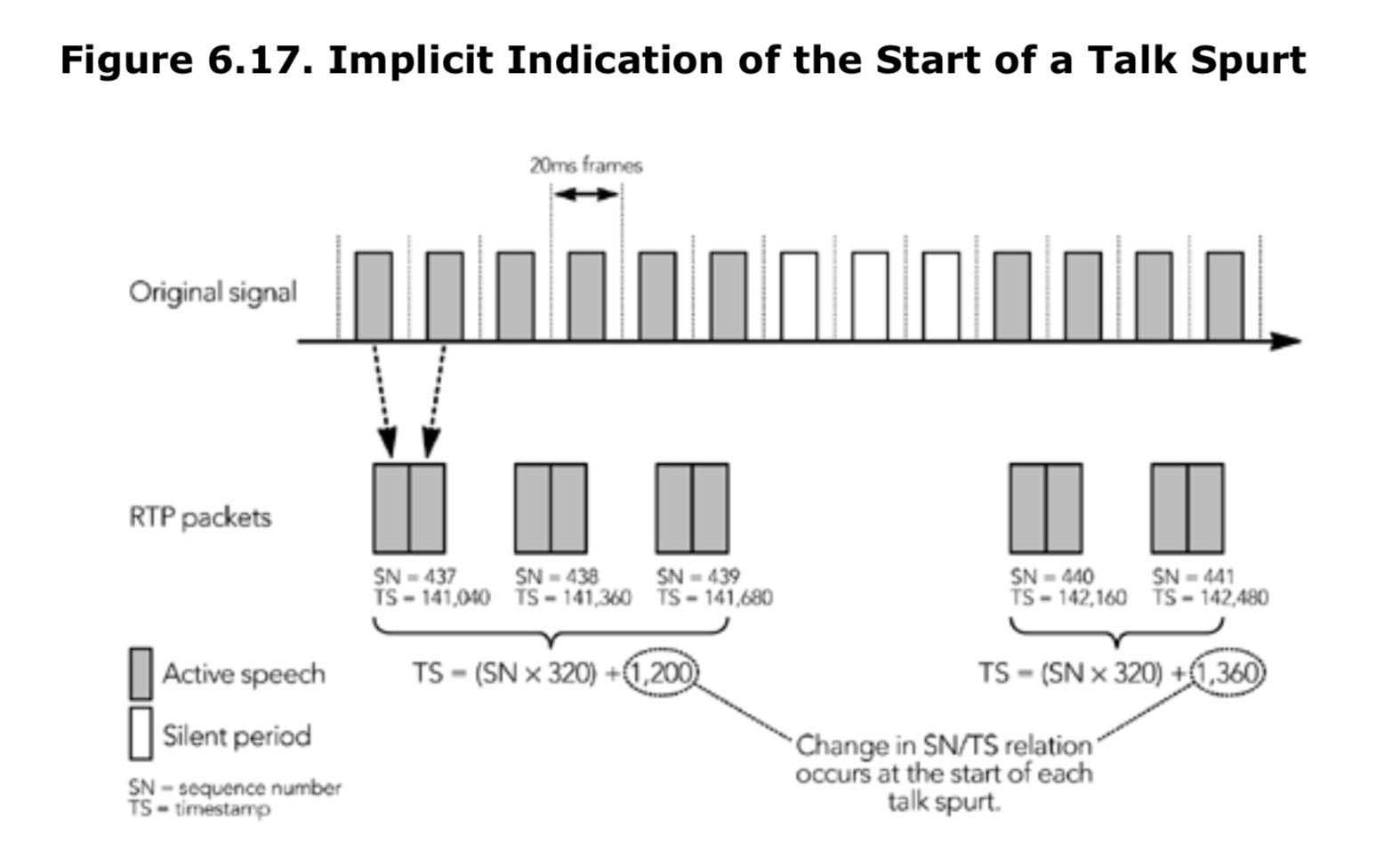
接收端通常很容易检测到通话期的开始,因为发送端需要在静默期之后设置第一个数据包上的标记位,以便明确的指示通话期的开始。然后,有时候,在一次通话期时,第一个信息包丢失了。通常仍然可以检测到一个新的通话期已经开始,因为序列号/时间戳的关系会发生改变,如图 6.17 所示,提供了一个关于通话期开始的隐式指示。
一旦确定了对话的开始,你可以通过稍微改变静音时间的长度来调整播放点。然而,对于通话期中的所有数据包,播放延迟保持不变。在假定条件不太可能发生显著变化的情况下,计算每次通话期间适当的播放延迟,用于调整后续通话期(talk spurt)的播放点。
一些语音编解码器在静音期间发送低速率的舒适噪声帧,以便接收端可以播放适当的背景噪声,以获得更愉快的收听体验。接收到一个舒适的噪声包表明一个谈话的结束,和一个适当的时间来调整播放延迟。舒适噪声周期的长度可以改变,但对音频质量没有显著影响。RTP 有效负载类型通常不会标识出舒适噪声帧,因此,有必要检查媒体数据,以检测它们的存在。不具有支持本机舒适噪声编解码功能的较旧的编解码器,可以将 RTP 有效负载格式用于舒适噪声,这由 RTP 负载类型 13 来标识。
在特殊情况下,可能有必要在通话尖峰期进行调整 -- 例如,如果多个数据包由于延迟到达而被丢弃。这些情况预计会很罕见,因为通话尖峰相对较短,网络条件通常变化缓慢。
将这些特性结合起来产生如下伪代码,以确定适当的时间来调整播放点,假设使用了静音抑制,如下所示:
int
should_adjust_playout(rtp_packet curr, rtp_packet prev, int contdrop)
{
if (curr->marker)
{
return TRUE; // Explicit indication of new talk spurt
}
delta_seq = curr->seq – prev->seq;
delta_ts = curr->ts - prev->ts;
if (delta_seq * inter_packet_gap != delta_ts)
{
return TRUE; // Implicit indication of new talk spurt
}
if (curr->pt == COMFORT_NOISE_PT) || is_comfort_noise(curr))
{
return TRUE; // Between talk spurts
}
if (contdrop > CONSECUTIVE_DROP_THRESHOLD)
{
contdrop = 0;
return TRUE; // Something has gone badly wrong, so adjust
}
return FALSE;
}
变量 contdrop 是计算由于不适当的播放时间而丢弃的连续数据包的数量。例如,如果路由更改导致数据包到达时间太晚而无法播放。CONSECUTIVE_DROP_THRESHOLDT 一个合适的值是三个数据包。
如果函数 should_playout()返回了 TRUE,则接收端要么处于静默期,要么错误的计算了播放点。如果计算的播放点偏离了当前使用的值,那么它应该通过更改计划的播放时间来调整未来包的播放点。不需要生成填充数据,只需要继续播放静音/舒适的噪音,直到下一个包被调度(即使调整是由多个连续的数据包丢弃触发的,也是如此,因为这表明播放已停止)。
当播放延迟正在减少时,需要注意,因为条件的重大变化,可能会使下一个讲话的突然开始时间提前到,与一个讲话突然结束的时间重叠。由于不希望限制通话期的开始,因此可执行的调整量会受到限制。
音频无静音抑制的播放调整
当接收到在没有静音抑制情况下传输的音频时,接收端必须在音频播放的同时调整播放点。最理想的调整方法是调整本地媒体时钟,使其与发送端的时钟相匹配,以便直接播放数据。如果这是不可能的,那就是因为缺少必要的硬件支持,接收端将不得不通过生成要插入到媒体流中的填充数据,或从播放缓冲区中删除一些媒体数据来改变播放点。这两种方法都不可避免的会对播出产生一些干扰,重要的是要隐藏调整的影响,以确保不会干扰听众。
根据输出设备的性质和接收端的资源,有几种可能的自适应算法:
- 音频可以在软件中重采样,以匹配输出设备的速率。标准信号处理教程提供了各种算法,这取决于所需的质量和资源的权衡。这是一个很好的通用解决方案。
- 根据对媒体的了解,可以对播放延迟进行逐个样本的调整。例如,Hodson 等人使用模式匹配算法来检测语音中的音调周期,这些音调周期会被删除或复制以适应播放效果(音调周期比完整帧要短得多,因此这种方法可以实现细粒度的适应)。与重采样相比,此方法可以执行得更好,但是它是特定于内容的。
- 完整的帧可以插入或者删除,就像数据包丢失或重复一样。这种算法质量通常不高,但是,如果使用了专为同步网络而设计的硬件解码器,则可能需要这种算法。
在没有静音抑制的情况下,没有明显的时间来调整播放点。 尽管如此,接收端仍然可以通过在错误隐藏更有效的时间(例如,在相对安静的时间段或信号高度重复的时间段内)更改播放(取决于编解码器和错误隐藏算法)来做出有关播放调整的明智选择。第八章《错误隐藏》中详细介绍了丢包隐藏策略。
视频播放自适应
视频是一种离散的媒体格式,在这种格式中,每一帧都在特定的时间点采样,帧与帧之间的间隔不会被记录。视频的离散特性,为播放算法提供了灵活性,可以允许接收端通过稍微改变帧间计时来自适应播放。不幸的是,显示设备通常以固定的速率运行并限制可能的显示时间。视频播放变成了一个最小化预期和可能的帧表示之间的偏差的问题。
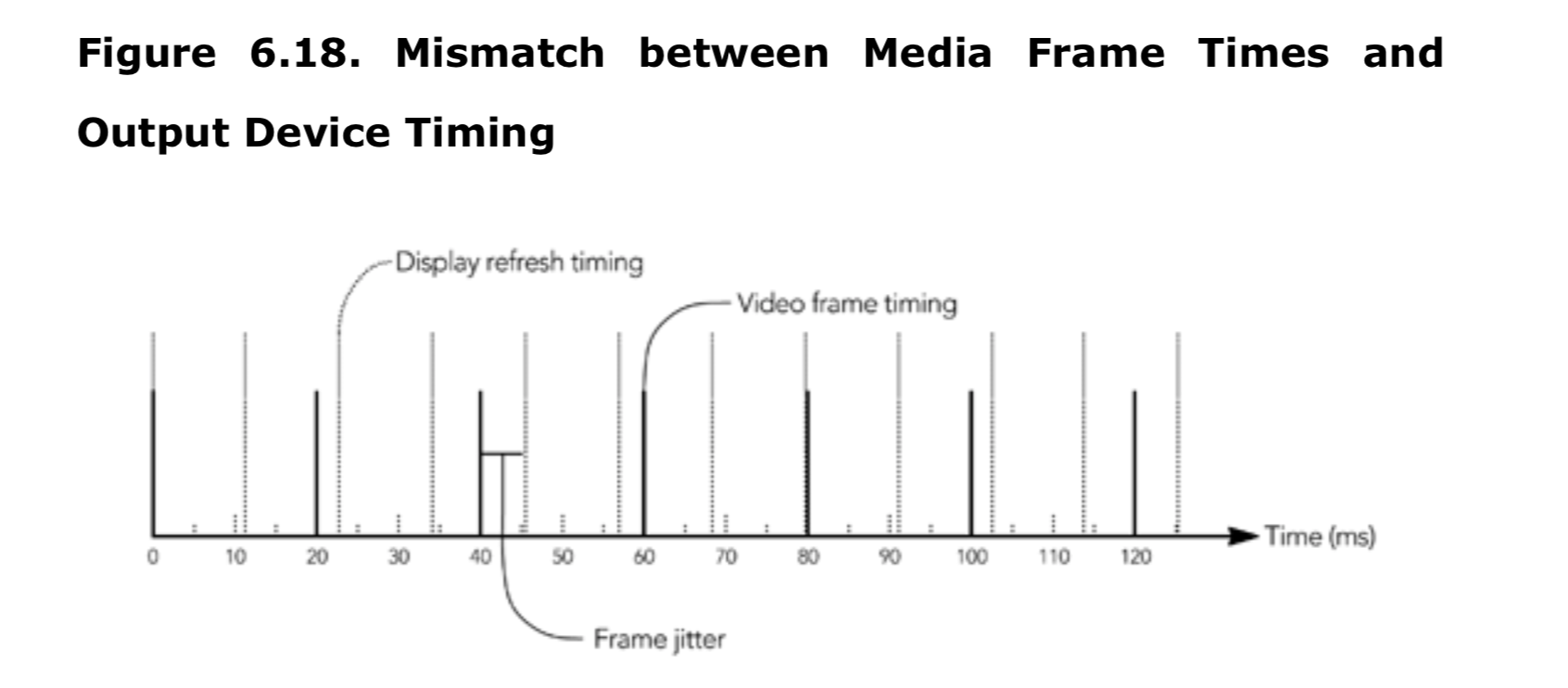
举个例子,考虑一下在刷新率为 85Hz 的监视器上显示每秒 50 帧的视频剪辑的问题。在这种情况下,监视器刷新时间将与视频播放时间不匹配,这将不可避免的导致帧呈现给用户的时间发生变化,如图 6.18 所示。只有改变采集设备的帧速率或者显示的刷新率才能解决这个问题。在实践中,这个问题目前是无解的,因为视频采集和回放设备通常对可能的速率有硬件限制。即使采集和回放设备,在名义上具备相同的速率,也可能需要根据抖动或者时钟偏移的影响调整播放。
存在三种可能的调整情况:(1)当显示设备的帧率高于采集设备时;(2)当显示设备的帧率低于采集设备时;(3)当显示和采集设备以相同帧率运行时。
如果显示设备的帧速率高于采集设备的帧速率,则可能的显示时间将围绕所需时间,并且每个帧都可以映射到唯一的显示刷新间隔。 最简单的方法是以最接近其播放时间的刷新间隔显示帧。可以通过朝任何所需的播放调整方向移动帧来获得更好的结果:如果接收端时钟相对较快,则在其播放时间之后的刷新间隔显示帧,如果接收端时钟较慢则以较早的间隔显示帧。当没有从发送端收到新帧时,可以通过重复前一帧来填充中间刷新间隔。
如果显示设备的帧率低于采集设备,则不可能显示所有帧,并且接收端必须丢弃一些数据。例如,接收端可以计算帧播放时间和显示时间之间的差异,并选择显示最接近可能显示时间的帧子集。
如果显示设备和采集设备以相同的速度运行,则可以滑动播放缓冲区,使得帧表示的时间与显示刷新时间一致,且滑动会提供一定程度的抖动缓冲延迟。这是一种不常见的情况:时钟偏移是常见的,周期性的抖动调整可能会打乱时间轴。根据需要调整方向,接收端必须插入或移除一个帧来进行补偿。
你可以简单的通过在两个间隔重复同一帧将一个帧插入到播放序列中。同样的,从序列中删除一个帧也是一个简单的事情。(请注意,可能会从一个未显示的帧中预估出其他帧,因此通常不可能在不解码的情况下完全丢弃一个帧,除非在完整帧之前的最后一个预测帧)。
无论如何进行调整,请注意,人类的视觉系统对不均匀的播放有一定的敏感性,接收端应该尽量保持帧间播放时间的均匀性,以防止干扰。在较小的播放调整(选择较早或较晚的显示帧时间)被证明不够时,插入或删除帧才最后被选择。
解码、混合和播放
播放过程的最后阶段是解码编码媒体,如果输出通道比活跃的源要少,则将媒体流混合在一起,最后向用户播放媒体。本节将依次考虑每个阶段。
解码
对于每个活跃的源,应用程序必须维护媒体解码器的实例,包括解码缩实例以及编码上文的状态。根据系统的不同,解码器可以是实际的硬件设备,也可以是软件功能。它根据帧中的数据和编码上下文,将每个编码帧转换为未编码的媒体数据。当每个帧被解码时,源的编码上下文将被更新,如图 6.19 所示。
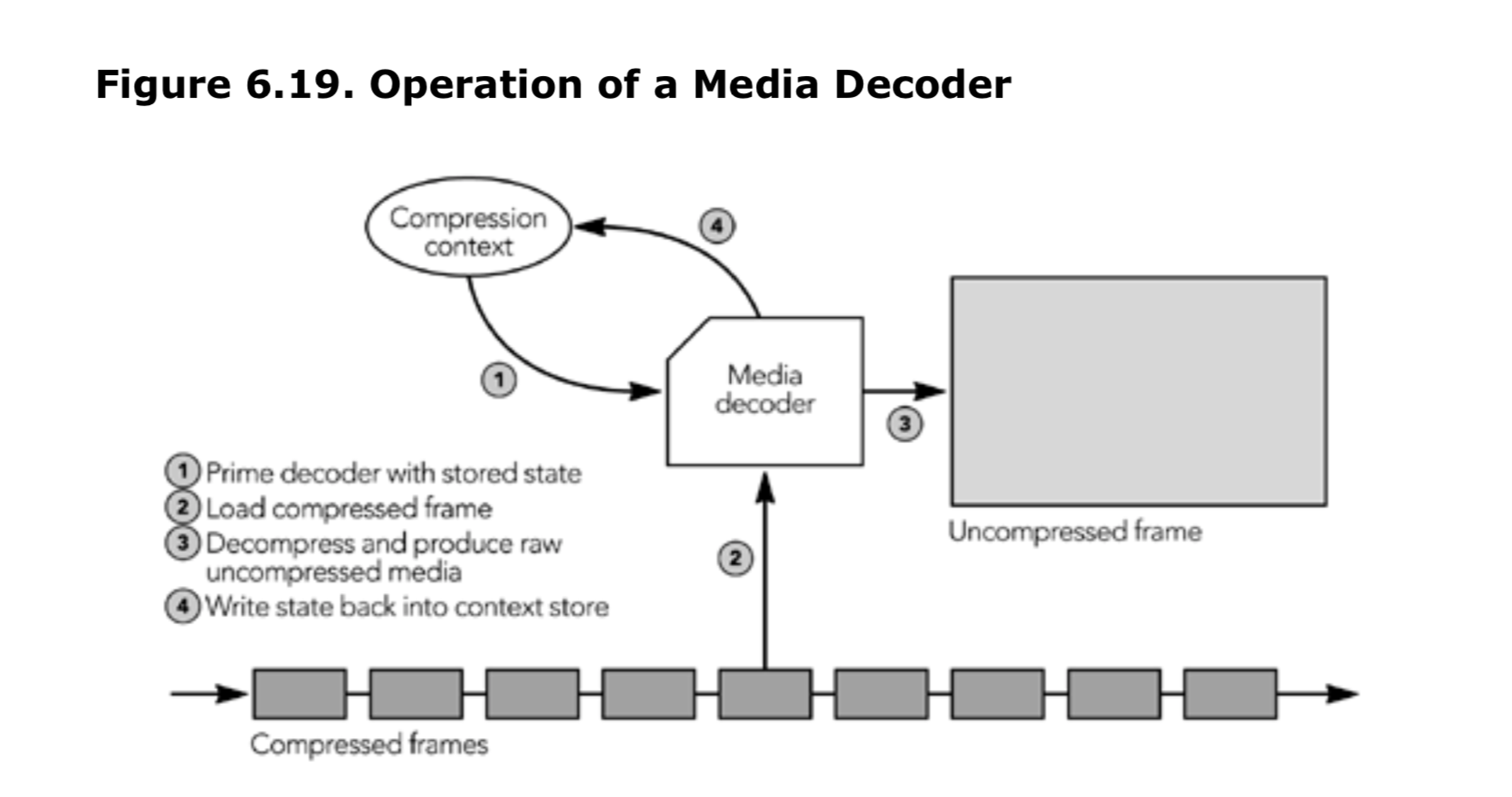
解码上下文的准确状态是解码器正确操作的基础,如果上下文丢失或者被损坏,编解码器将产生错误的结果。这是最常见的问题,如果一些数据包丢失,那么将有一个无法解码的帧。结果是该帧本应播出的地方出现空隙,并且解码上下文也将失效,下面的帧也会被破坏。
根据编解码器的不同,可能会像它提供帧丢失的标记,从而使解码器能够更好的修复上下文并减少对媒体流的损害(例如,许多语音编解码器都有消除帧的概念以标识信号丢失)。否则,接收端应设法修复上下文并隐藏丢包的影响,如第八章“错误隐藏”所述。许多丢失隐藏算法对未编码的媒体数据进行解码、混合和播放操作。
混音
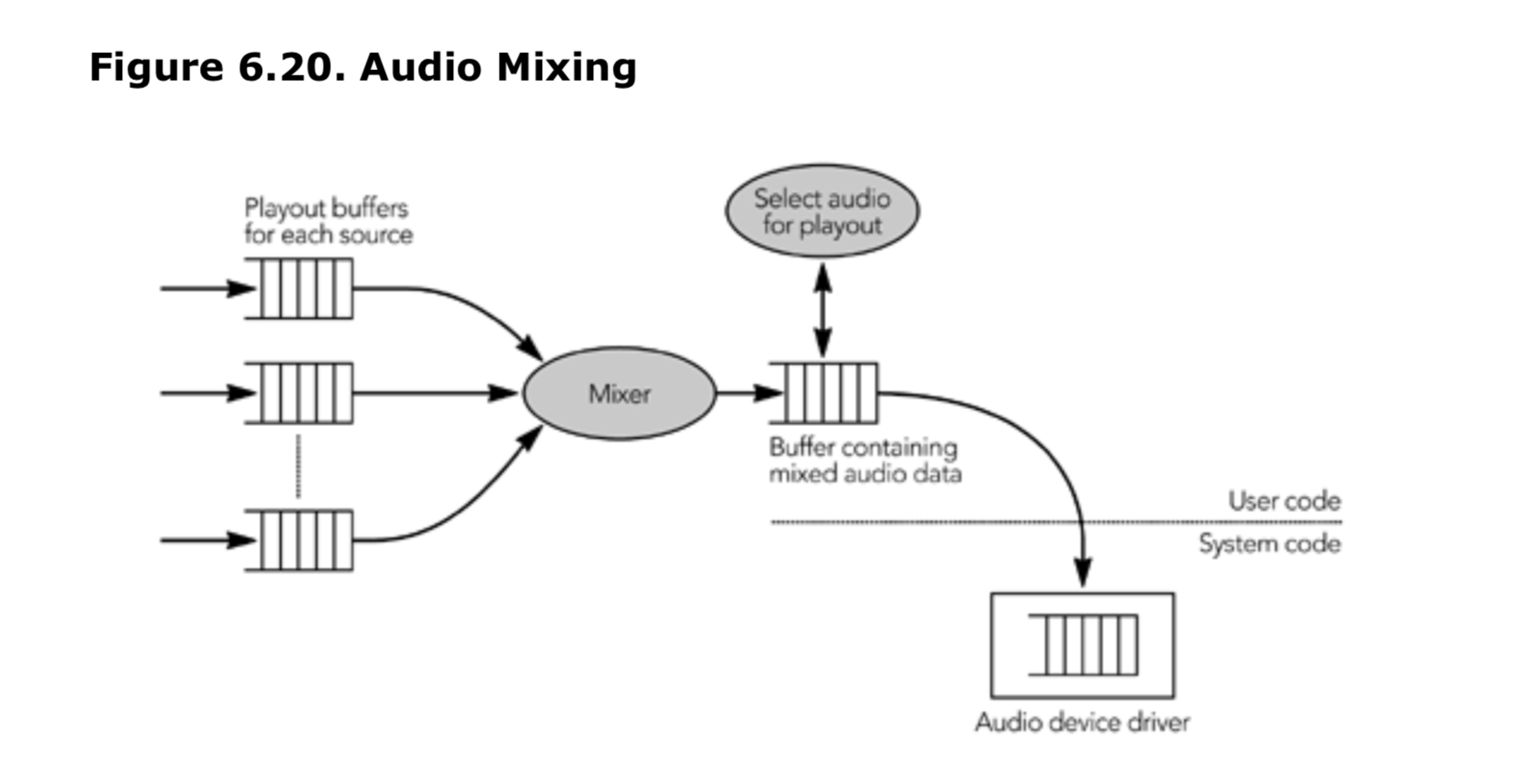
混合是将多个媒体流组合成一个输出的过程。这主要是音频应用程序的一个问题,因为大多数的系统只有一组扬声器,但是有可能会存在多个活跃的源 -- 例如,在多方的电话会议场景中。音频流被解码后,必须在写入音频设备之前将它们混合在一起。音频工具的最后阶段的结构通常如图 6.20 所示。解码器在每个源的基础上,产生未编码的音频数据,写入每个源的播放缓冲区,混音器将结果组合成单个播放缓冲区(当然,如果解码器理解混合过程,这些步骤可以组合成一个)。混音可以在媒体被解码后的任何时间发生,也可以在它被播放之前。
混音缓冲区最初是空的,即充满了静音,每个参与者的音频依次混合到缓冲区中。最简单的混音方法是使用饱和加法,其中每个参与者的音频依次加入到缓冲区中,溢出条件是在极值处饱和。在伪代码中,假设有 16bit 样本,并将一个新的参与(src)混合到缓冲区(mix_buffer)中,这将变成:
audio_mix(sample *mix_buffer, sample *src, int len)
{
int i, tmp;
for(i = 0; i < len; i++)
{
tmp = mix_buffer[i] + src[i];
if (tmp > 32767)
{
tmp = 32767;
}
else if (tmp < -32768)
{
tmp = -32768;
}
mix_buffer[i] = tmp;
}
}
如果需要更高保真度的混音,可以使用其他算法。SIMD 处理器通常有混合采集样本的指令。 例如,英特尔 MMX(多媒体扩展)指令包括饱和加法指令,该指令一次添加四个 16bit 样本,并且由于混合循环不再有分支检查,因此性能最高可提高十倍。
实际的混合缓冲区可以实现为循环缓冲区。 缓冲区被实现为具有开始和结束指针的数组,并环绕以给出连续缓冲区的错觉(参见图 6.21)。
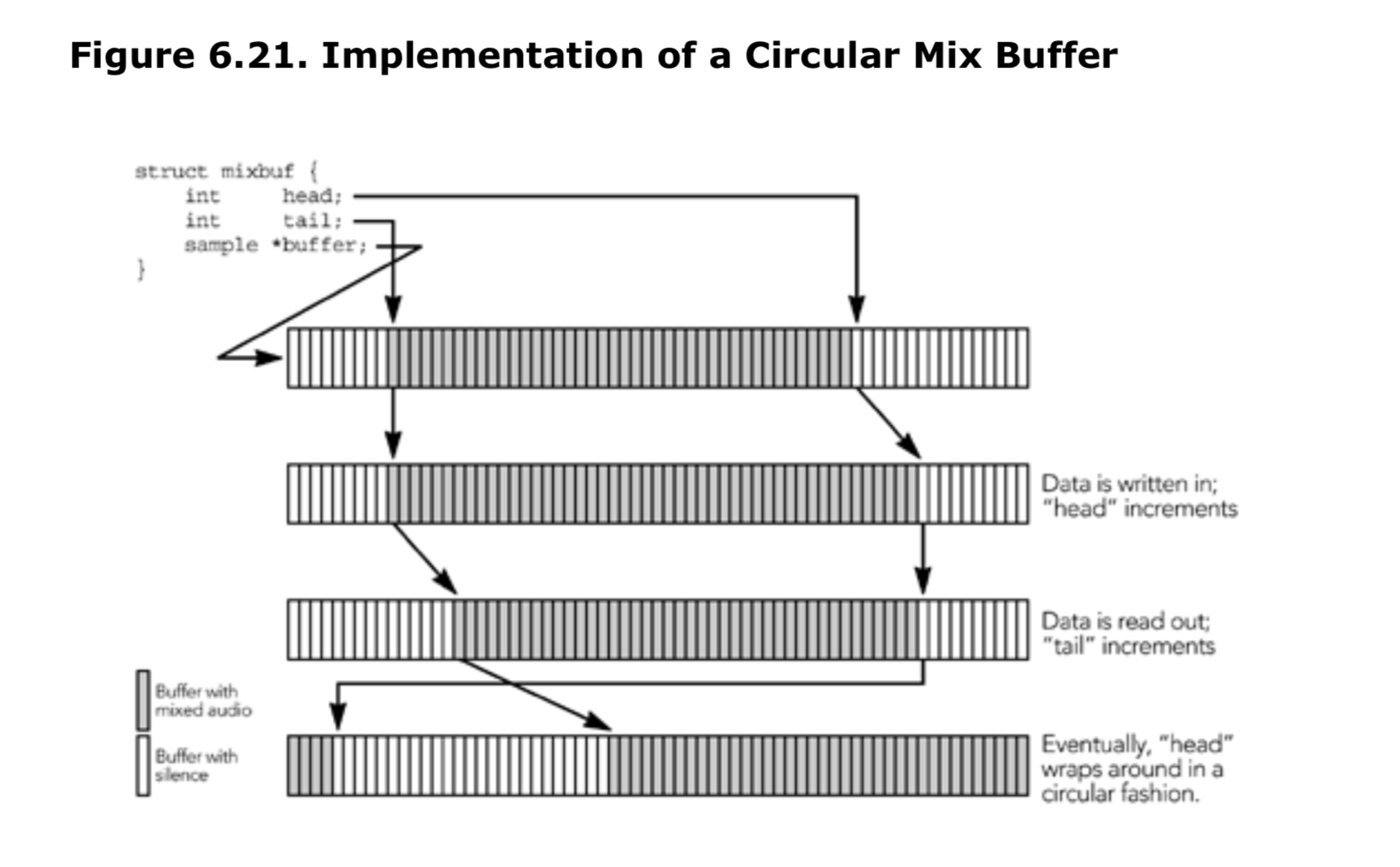
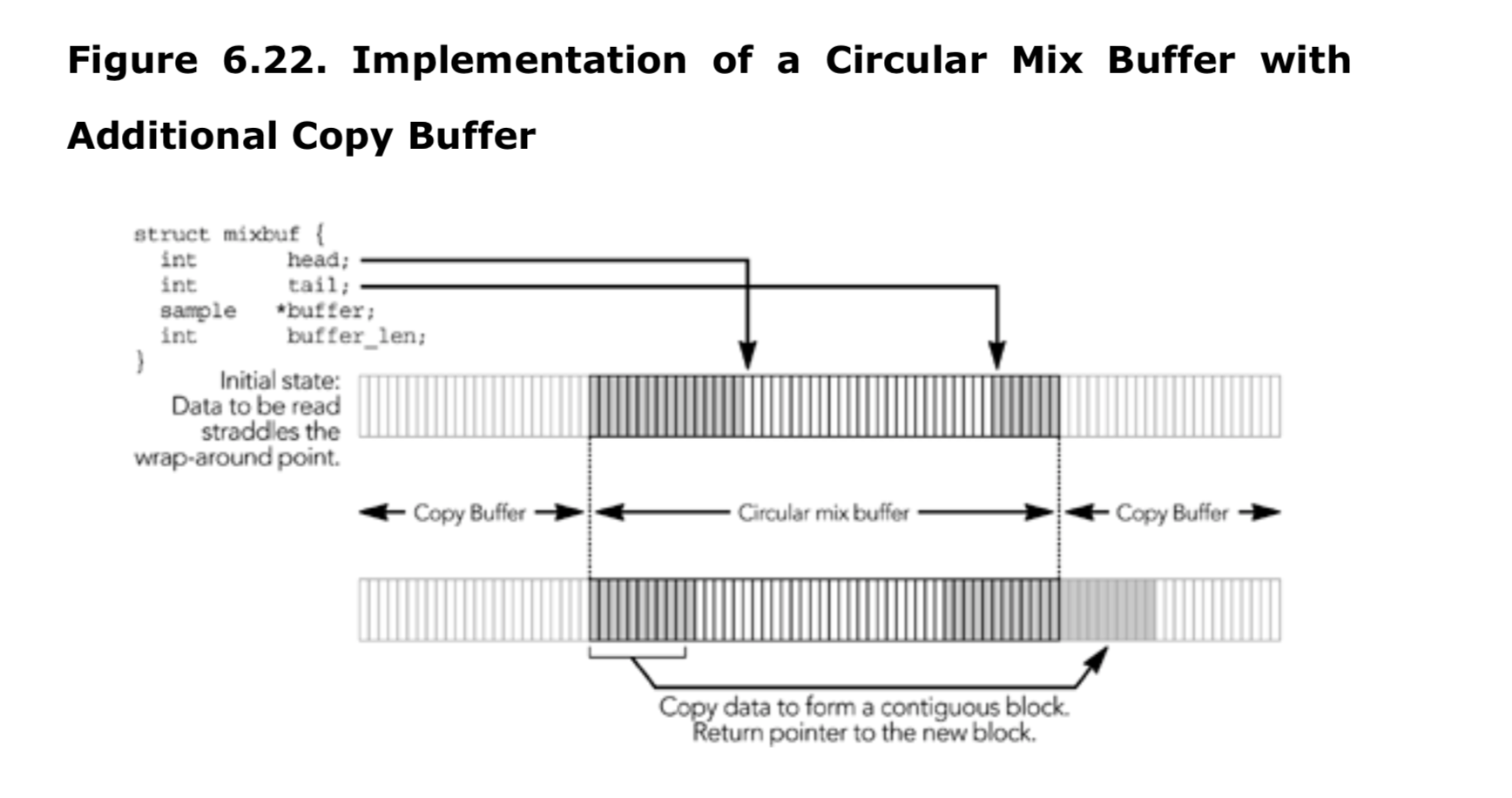
简单循环缓冲区的限制是,它不能总是使其模拟的连续缓冲区可供读取。相反,当读数接近环绕点时,将需要返回两个混合数据块:一个来自循环缓冲区的末端,一个来自循环缓冲区的开始。如果分配的数据大小是所需大小的两倍,则可以避免返回两个缓冲区。如果负责读的实例,请求一个包含循环缓冲区中翻转点的块,则混音器可以将数据复制到附加的空间中,并返回指向连续内存的指针,如图 6.22 所示。这需要额外的音频数据副本,最大为循环缓冲区的一半,但允许读取返回单个连续缓冲区,从而简化了使用混音器的代码。循环缓冲区的正常操作没有改变,只是在读取数据时进行了一次复制。
音频的播放
向用户播放音频的过程通常是异步的,允许系统在处理下一帧音频的同时播放一帧音频。此功能对于正常操作至关重要,因为即使应用程序忙于 RTP 和媒体处理,它也可以连续播放。它还可以保护应用程序免受系统行为的影响,这可能是由于该系统上正在运行其他应用程序所致。
异步播放在对多媒体应用程序支持有限的通用操作系统上尤其重要。这些系统通常设计为提供良好的平均响应,但是它们常常不希望出现最坏的情况,并且通常不能保证实时应用程序得到适当的调整。应用程序可以充分利用异步播放,使用音频 DMA(内存直接访问)硬件来保持连续播放。如图 6.23 所示,应用程序可以监视输出缓冲区占用的情况,并根据上一次调整以后的时间来调整写入音频设备的数量,这样每次迭代后的缓冲区占用情况都是恒定的。
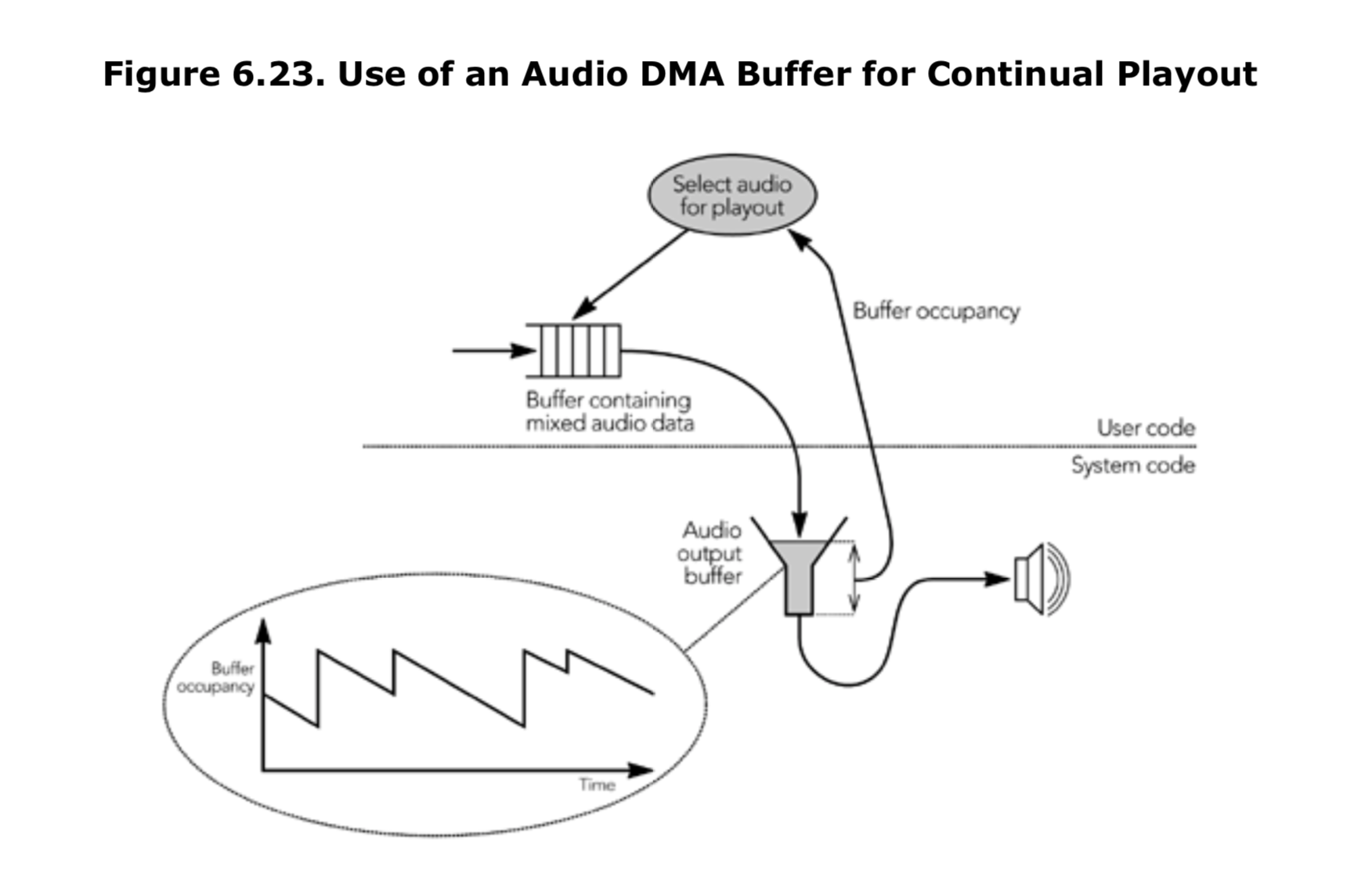
如果应用程序检测到一段不同寻常的调度延迟(可能是由于系统上的大量磁盘活动),它可以抢先增加音频 DMA 缓冲区大小,直到达到播放点的限制。如果操作系统,不允许直接监视缓冲和等待播放的音频的数量,则有可能从等待读取的音频量中得出估算值,以用于应用程序的编码端。在许多情况下,音频回放和录制是由相同的硬件时钟驱动的,因此,应用程序可以计算它记录的音频样本数量,并使用这些信息来获取回放缓冲区占用的情况。对音频 DMA 缓冲区的监控,可以确保在除了最极端的环境之外的所有环境中可以连续的播放。
视频播放
视频播放很大程度上是由显示器的刷新率决定的,它决定了应用程序写入到输出缓冲区,到将图像呈现给用户之间的最大时间间隔。平滑视频播放的关键是两个方面:(1)帧应该以均匀的速率呈现,(2)在视频呈现时,应该避免帧的变化。第一点是关于播放缓冲区的问题,选择适当的显示时间,如本章前面的视频播放调整部分所述。
第二点与显示有关:帧不是即时呈现的;相反,它们被画成一系列的扫描线,从左到右,从上到下。这种串行表示允许应用程序在显示帧时,可以更改帧,从而会导致输出出现故障。双缓冲可以解决这个问题,一个缓冲区用来组成帧,而第二个缓冲区用来显示。两个缓冲器在帧之间进行切换,并与帧间间隔同步。实现双缓冲的方法依赖于系统,但是,通常是视频显示 API 的一部分。
总结
本章描述了 RTP 发送端和接收端的基本行为,重点介绍了接收端的播放缓冲区的设计。对于,可以接受几百毫秒(甚至几秒)延迟的流式应用程序,播放缓冲区的设计会相对简单。然而,对于为交互使用而设计的应用程序,播放缓冲区对于获得良好的性能至关重要。这些应用程序需要较低的延迟,因此,缓冲区的延迟只有几十毫秒,这就增加了算法设计的工作量,因为算法必须平衡低延迟的需要和避免丢弃延迟的包(如果可能的话)。
RTP 系统在终端系统中设置了很多的技巧(intelligence)使得它们能够弥补在最佳的分组网络中具备固有的可变性。认识到这一点,是获得良好性能的关键:一个设计良好、健壮的实现,可以比一个简单的设计执行的要好得多。